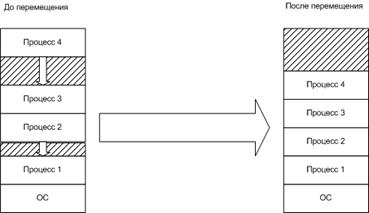
1. Определение
ОС. Назначение и функции операционной системы
2. Место ОС в структуре вычислительной системы
3. Понятие ресурса. Управление ресурсами в вычислительной
системе
4. Критерии эффективности и классы ОС
6. Современный этап развития ОС
7. Функциональные компоненты ОС персонального компьютера
8. Требования, предъявляемые к современным ОС
10. Архитектура ОС. Ядро и вспомогательные модули
11. Классическая архитектура ОС. Монолитные и многослойные
ОС
12. Микроядерная архитектура ОС
13. Многослойная модель ядра ОС
14. Функции ОС по управлению процессами
17. Планирование и диспетчеризация потоков, моменты
перепланировки
18. Алгоритм планирования, основанный на квантовании
22. Алгоритм планирования
Windows NT
23. Планирование в ОС реального времени
24. Синхронизация процессов и потоков: цели и средства
синхронизации
25. Ситуация состязаний (гонки). Способы предотвращения.
27. Взаимные блокировки. Условия, необходимые для
возникновения тупика
28. Обнаружение взаимоблокировки при наличии одного
ресурса каждого типа
29. Обнаружение взаимоблокировок при наличии нескольких
ресурсов каждого типа
30. Предотвращение взаимоблокировки. Алгоритм банкира для
одного вида ресурсов
31. Предотвращение взаимоблокировки. Алгоритм банкира для
нескольких видов ресурсов
33. Организация обмена данными между процессами (каналы,
разделяемая память, почтовые ящики, сокеты)
34. Функции ОС по управлению памятью
37. Страничное распределение памяти
Дескриптор страницы включает в себя следующую
информацию:
38. Таблицы страниц для больших объемов памяти
39. Алгоритмы замещения страниц.
Алгоритм удаляет произвольную страницу низшего класса.
40. Сегментное распределение памяти.
41. Сегментно-страничное распределение памяти.
42. Средства поддержки сегментации памяти в МП Intel Pentium.
43. Сегментный режим распределения памяти в МП Intel Pentium.
44. Сегментно-страничный режим распределения памяти в МП Intel Pentium.
45. Средства защиты памяти в МП Intel Pentium.
46. Кэш-память (понятие, принцип действия кэш-памяти).
47. Случайное отображение основной памяти на кэш.
48. Детерминированное отображение основной памяти на кэш.
49. Комбинированный способ отображения основной памяти на
кэш.
50. Кэширование в МП Intel Pentium. Буфер ассоциативной
трансляции
51. Кэширование в МП Intel Pentium. Кэш первого уровня
52. Задачи ОС по управлению файлами и устройствами
53. Многослойная модель подсистемы ввода-вывода
54. Физическая организация жесткого диска.
55. Файловая система. Определение, состав, типы файлов.
Логическая организация файловой системы.
56. Физическая организация и адресация файлов.
57. FAT. Структура тома. Формат записи каталога. FAT12,
FAT16, FAT32.
59. UFS : структура тома, адресация файлов, каталоги,
индексные дескрипторы.
61. NTFS: типы файлов, организация каталогов.
62. Файловые операции. Процедура открытия файла.
63. Организация контроля доступа к файлам.
64. Контроль доступа к файлам на примере Unix.
65. Отказоустойчивость файловых систем.
66. Процедура самовосстановления NTFS.
67. Избыточные
дисковые подсистемы RAID.
72. Симметричные
алгоритмы шифрования.
73. Шифрование с открытым ключом.
74. Односторонние
функции шифрования.
75. Параметры, свойства и показатели эффективности ОС.
76. Основные и частные показатели эффективности ОС.
77. Мониторинг производительности ОС.
78. Настройка и оптимизация ОС.
79. Прерывания (понятие, классификация, обработка
прерываний).
81. Механизм вызова при переключении между задачами.
82. Обработка аппаратных прерываний.
1. Определение ОС. Назначение и функции операционной
системы
Операционная система – комплекс взаимосвязанных программ, обеспечивающих
взаимодействие пользователя с вычислительной системой, а также управления
ресурсами вычислительной системы.
Функции:
· Предоставление пользователю вместо реальной аппаратуры виртуальной машины (виртуальной аппаратуры);
· Повышенная эффективность использования аппаратуры путём рационального использования ресурсов.
Ресурсы: память, процессорное время, устройства ввода\вывода.
2. Место ОС в структуре вычислительной системы
Вычислительная система – программно-аппаратный комплекс, который предоставляет услуги пользователю.
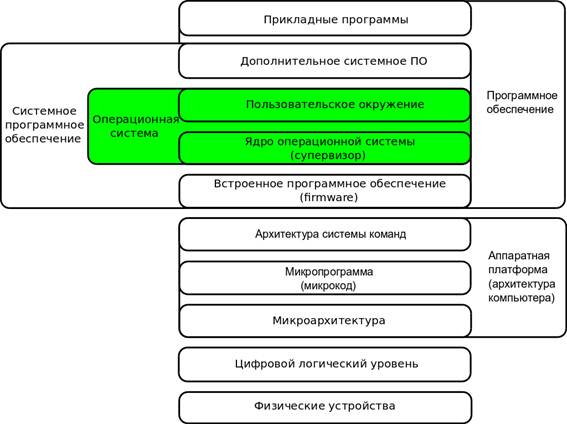
Рисунок 1. Структура вычислительной системы
|
Прикладные программы |
|
||||||
|
Системы программирования |
|
||||||
|
Управление логическими устройствами |
|
||||||
|
Управление физическими устройствами |
|
||||||
|
Аппаратные средства |
||||||||
Таблица 1. Вычислительная система
Аппаратные средства – нижний уровень - это аппаратура, то, что делается из металла, пластика и прочих материалов, используемых для производства «железа» компьютера.
Управление физическими устройствами осуществляют программы, ориентированные на качества и свойства аппаратуры, взаимодействующие с аппаратными структурами, знающие «язык» аппаратуры.
Уровень управления логическими устройствами ориентирован на пользователя, предназначен для сглаживания аппаратных особенностей устройств. Команды этого уровня обращены к предыдущему слою.
Система программирования – это комплекс программ для поддержки всего технологического цикла разработки программного обеспечения.
Прикладные программы предназначены для решения некоторых задач в конкретных областях знаний.
К ОС относят второй и третий уровень пирамиды. в начало
3. Понятие ресурса. Управление ресурсами в вычислительной
системе
Ресурс – всякий объект, который может распределяться внутри ОС.
· процессоры (процессорное время)
· память
· периферийные устройства (диски, таймеры, наборы данных, принтеры, сетевые устройства и т.п.)
Ресурсы могут быть:
· разделяемые (несколько процессов используют их одновременно) и неделимые
· выгружаемые (могут быть отобраны у процесса без негативных последствий – например, оперативная память) и невыгружаемые (принудительная выгрузка приводит к сбою – например, компакт-диск)
Управление ресурсами включает в себя решение следующих задач:
· планирование ресурса (когда, кому и в каком объёме)
· удовлетворение запросов на ресурсы
· отслеживание состояния и учёт использования ресурса
· разрешение конфликтов между процессами в начало
4. Критерии эффективности и классы ОС
|
Класс ОС |
Критерий эффективности |
|
ОС пакетной обработки |
Максимальная пропускная способность (максимальная загрузка процессора) |
|
Интерактивные ОС (ОС разделения времени) |
Удобство работы пользователя |
|
ОС реального времени |
Реактивность (гарантированное время реакции системы на то или иное событие) |
Главной целью и критерием эффективности систем пакетной обработки является максимальная пропускная способность, т.е. решение максимального числа задач в единицу времени. Для достижения этой цели в системах пакетной обработки используется следующая схема функционирования: в начале работы формируется пакет заданий, каждое задание содержит требования к системным ресурсам; из этого пакета формируется мультипрограммная смесь, то есть множество одновременно выполняемых задач. Для одновременного выполнения выбираются задачи, предъявляющие разные требования к ресурсам, так, чтобы обеспечивалась сбалансированная загрузка всех устройств вычислительной машины. Выбор нового задания из пакета заданий зависит от внутренней ситуации, складывающийся в системе. Следовательно, в вычислительных системах, работающих под управлением пакетных ОС, невозможно гарантировать выполнение того или иного задания в течение определенного периода времени.
Цель планирования в системах разделения времени - повышение удобства и эффективности работы пользователя. В системах разделения времени пользователям (или одному пользователю) предоставляется возможность интерактивной работы сразу с несколькими приложениями. ОС принудительно периодически приостанавливает приложения, не дожидаясь, когда они добровольно освободят процессор. Всем приложениям попеременно предоставляется квант процессорного времени, таким образом, что пользователи, запустившие программы на выполнение, получают возможность поддерживать с ними диалог.
ОС реального времени предназначены для управления различными техническими объектами или технологическими процессами. В таких системах мультипрограммная смесь обычно представляет собой фиксированный набор заранее разработанных программ, а выбор программы на выполнение осуществляется по прерываниям (исходя из состояния управляемого объекта) или в соответствии с расписанием плановых работ. Критерий эффективности работы ОС реального времени – способность системы выдерживать заранее заданные интервалы времени между запуском программы и получением результата (реактивность системы). в начало
5. Эволюция ОС
Первый период (1945 -1955). В середине 40-х были созданы первые ламповые вычислительные устройства (в США и Великобритании), в СССР первая ламповая вычислительная машина появилась в 1951 году. Программирование осуществлялось исключительно на машинном языке. Элементная база – электронные лампы и коммуникационные панели. Операционных систем не было, все задачи организации вычислительного процесса решались вручную программистом с пульта управления. Системное программное обеспечение - библиотеки математических и служебных подпрограмм.
Второй период (1955 - 1965). С середины 50-х годов начался новый период в развитии вычислительной техники, связанный с появлением новой технической базы - полупроводниковых элементов (транзисторы). В эти годы появились первые алгоритмические языки и, следовательно, первые системные программы - компиляторы. Стоимость процессорного времени возросла, что потребовало уменьшения непроизводительных затрат времени между запусками программ. Появились первые системы пакетной обработки, увеличивающие коэффициент загрузки процессора. Системы пакетной обработки явились прообразом современных операционных систем, они стали первыми системными программами, предназначенными для управления вычислительным процессом. Был разработан формальный язык управления заданиями. Появился механизм виртуальной памяти.
Третий период (1965 - 1975). Переход к интегральным микросхемам. Создание семейств программно-совместимых машин (серия машин IBM System/360, советский аналог - машины серии ЕС). В этот период времени были реализованы практически все основные концепции, присущие современным ОС: мультипрограммирование, мультипроцессирование, многотерминальный режим, виртуальная память, файловая система, разграничение доступа и сетевая работа. В процессорах появился привилегированный и пользовательский режим работы, специальные регистры для переключения контекстов, средства защиты областей памяти и система прерываний. Другое нововведение - спулинг (spooling). Спулинг в то время определялся как способ организации вычислительного процесса, в соответствии с которым задания считывались с перфокарт на диск в том темпе, в котором они появлялись в помещении вычислительного центра, а затем, когда очередное задание завершалось, новое задание с диска загружалось в освободившийся раздел. Появился новый тип ОС - системы разделения времени. В конце 60-х годов начаты работы по созданию глобальной сети ARPANET, ставшей отправной точкой для Интернета. К середине 70-х годов широкое распространение получили мини-компьютеры. Их архитектура была значительно упрощена по сравнению с мейнфреймами, что нашло отражение и в их ОС. Экономичность и доступность мини-компьютеров послужила мощным стимулом к созданию первых локальных сетей. С середины 70-х годов началось массовое использование ОС UNIX. В конце 70-х был создан рабочий вариант протокола TCP/IP, в 1983 году он был стандартизирован.
Четвертый период (1980 - настоящее время). Следующий период в эволюции операционных систем связан с появлением больших интегральных схем (БИС). В эти годы произошел резкий рост степени интеграции и удешевление микросхем. Наступила эра персональных компьютеров. Компьютеры стали широко использоваться неспециалистами. Реализован графический интерфейс пользователя (GUI - Graphical User Interface), теория которого была разработана еще в 60-е годы. С 1985 года стала выпускаться Windows, это была графическая оболочка MS-DOS вплоть до 1995г., когда вышла полноценная ОС Windows 95. IBM и Microsoft совместно разработали операционную систему OS/2. Она поддерживала вытесняющую многозадачность, виртуальную память, графический пользовательский интерфейс, виртуальную машину для выполнения DOS-приложений. Первая версия вышла 1987 г. В дальнейшем Microsoft отказалась от OS/2 и приступила к разработке Windows NT. Первая версия вышла в 1993г.
В 1987г. была выпущена операционная система MINIX (прототип LINUX), она была построена по принципу микроядерной архитектуры.
В 80-е годы были приняты основные стандарты на коммуникационное оборудование для локальных сетей: в 1980 году –Ethernet, в 1985 – Token Ring, в конце 80-х – FDDI. Это позволило обеспечить совместимость сетевых ОС на нижних уровнях, а также стандартизировать интерфейс ОС с драйверами сетевых адаптеров.
В 90-е годы практически все ОС стали сетевыми. Появились специализированные ОС, предназначенные исключительно для решения коммуникационных задач (IOS компании Cisco Systems). Появление службы World Wide Web (WWW) в 1991 году придало мощный импульс развитию популярности Интернета. Развитие корпоративных сетевых операционных систем выходит на первый план. Возобновляется развитие ОС мейнфреймов. В 1991г. была выпущена LINUX. Чуть позже вышла FreeBSD (основой для нее послужила BSD UNIX). в начало
6. Современный этап развития ОС
В 90е годы практически все ОС стали сетевыми, эти функции включались в ядро. Полная совместимость с основными технологиями локальных и глобальных сетей. Особое внимание в течении всего последнего десятилетия уделялось корпоративным сетевым ОС. Их дальнейшее развитие представляет одну из наиболее важных задач и в обозримом будущем. Для таких сетей важно наличие средств централизованного администрирования и управления. Для них так же важно в силу их гетерогенности наличие и следование множеству стандартов.
Так же на современном этапе развития ОС на первый план вышли средства обеспечения безопасности. Огромное значение имеет многоплатформенность (переносимость). Повышается удобство работы человека с компьютером. в начало
7. Функциональные компоненты ОС персонального компьютера
1) Подсистема управления процессором: распределяет процессорное время, создает и уничтожает процессы, создает контекст процесса, наделяет процессы ресурсами, выполняет синхронизацию процессов, реализует межпроцессное взаимодействие.
2) Подсистема управления памятью: организует виртуальную память, отслеживает свободную и занятую память, выделение памяти процессам и освобождение её, настройка адресов программы на нужную область физической памяти, динамическое выделение памяти, защита памяти (аппаратно и программно), возможно дефрагментация памяти.
3) Подсистема управления файлами и внешними устройствами: хранение данных на дисках, организация параллельной работы устройств ввода\вывода, согласование скоростей обмена данных между процессором и устройствами, разделение устройств и данных между процессами, организация удобного интерфейса для других частей системы, поддержка широкого спектра драйверов и малого времени включения нужного драйвера при обнаружении нужного устройства, поддержка нескольких файловых систем, а так же синхронных и асинхронных операций.
4) Защита данных и администрирование: защита от сбоев аппаратуры (резервирование), ошибки ПО, защита от несанкционированного доступа, процедура логического входа (аутентификация), подтверждение прав доступа (авторизация), средства аудита
5) Прикладной программный интерфейс в начало
8. Требования, предъявляемые к современным ОС
·
максимальная
скорость выполнения
·
прозрачность
работы служебных программ (незаметность)
·
гарантированная
надежность
·
минимальность
машинного кода
·
использование
стандартных средств для связи с прикладными программами
·
расширяемость,
переносимость, совместимость
·
надежность,
отказоустойчивость
Расширяемость - код должен быть написан так, чтобы систему можно было легко наращивать и модифицировать по мере изменения потребностей рынка. В то время как аппаратная часть компьютера устаревает за несколько лет, полезная жизнь операционных систем может измеряться десятилетиями. Сохранение целостности кода, какие бы изменения не вносились в операционную систему, является главной целью. Расширяемость достигается за счет модульной структуры ОС и использования объектов для представления системных ресурсов.
Переносимость (многоплатформенность) дает возможность перемещать всю систему на машину, базирующуюся на другом процессоре или аппаратной платформе, делая при этом по возможности небольшие изменения в коде
Совместимость - способность ОС выполнять программы, написанные для других ОС или для более ранних версий данной ОС, а так же для других аппаратных платформ. Различают двоичную совместимость и сов. на уровне исходного кода. Для последней хватит лишь совместимости на уровне системных вызовов и наличия нужного компилятора. Используется эмуляция и виртуальные машины. в начало
9. Классификации ОС.
· По типу управления ресурсами
· По числу одновременно выполняемых задач: однозадачные(MS-DOS, MSX) и многозадачные(MS Dos, Linux,Windows);
· По числу одновременно работающих пользователей: однопользовательские(MS-DOS, Windows 3.x, ранние версии OS/2), многопользовательские(UNIX, Windows NT);
· По способу распределения времени: невытесняющая многозадачность (NetWare, Windows 3.x),вытесняющая многозадачность (Windows NT, OS/2, UNIX);
· Поддержка многопоточности;
· Многопроцессорная обработка: асимметричная ОС(целиком выполняется только на одном из процессоров системы, распределяя прикладные задачи по остальным процессорам),симметричная ОС (полностью децентрализована и использует весь пул процессоров, разделяя их между системными и прикладными задачами);
· По типу аппаратных платформ: ОС персональных компьютеров, ОС миникомпьютеров, ОС мейнфреймов, ОС кластеров, ОС сетей ЭВМ;
· По областям использования: пакетные, разделения времени, реального времени;
· По способу структурной организации: классические, микроядерные. в начало
10.
Архитектура ОС.
Ядро и вспомогательные модули
Операционная система состоит из ядра и вспомогательных
модулей.
Ядро выполняет:
· базовые функции ОС (управление процессами, памятью, устройствами ввода/вывода;
· функции, решающие внутрисистемные задачи организации вычислительного процесса, (переключение контекстов, загрузка/выгрузка страниц, обработка прерываний). Эти функции недоступны для приложений;
· функции для поддержки приложений, создающие для них прикладную программную среду. Приложения могут обращаться к ядру с запросами (системными вызовами) для выполнения тех или иных действий. Функции ядра, которые могут вызываться приложениями, образуют интерфейс прикладного программирования – API.
Для обеспечения высокой скорости работы все модули ядра или большая их часть постоянно находятся в оперативной памяти, то есть являются резидентными. Кроме того, одним из определяющих свойств ядра является работа в привилегированном режиме.
Вспомогательные модули ОС обычно подразделяются на следующие группы:
· утилиты – программы, решающие отдельные задачи управления и сопровождения компьютерной системы, например, программы сжатия диска, архивирования и т.д.
· системные обрабатывающие программы – текстовые и графические редакторы, компиляторы, компоновщики, отладчики;
· программы дополнительных услуг – специальный вариант пользовательского интерфейса, калькулятор, игры;
· библиотеки процедур – библиотека математических функций, функций ввода/вывода и т.д. в начало
11.
Классическая архитектура
ОС. Монолитные и многослойные ОС
Монолитное ядро представляет собой набор процедур, каждая из которых может вызвать каждую. Все процедуры работают в привилегированном режиме. Таким образом, монолитное ядро - это такая схема организации операционной системы, при которой все ее компоненты являются составными частями одной программы, используют общие структуры данных и взаимодействуют друг с другом путем непосредственного вызова процедур. Для монолитной операционной системы ядро совпадает со всей системой. Монолитное ядро - старейший способ организации операционных систем.
Такая организация ОС предполагает следующую структуру:
· Главная программа, которая вызывает требуемые сервисные процедуры.
· Набор сервисных процедур, реализующих системные вызовы.
· Набор утилит, обслуживающих сервисные процедуры.
Многослойная ОС - организация ОС как иерархии уровней с хорошо определенными связями между ними, так чтобы объекты уровня N могли вызывать только объекты из уровня N-1. Нижним уровнем в таких системах обычно является аппаратура, верхним уровнем интерфейс пользователя. Чем ниже уровень, тем более привилегированные команды и действия может выполнять модуль, находящийся на этом уровне. Уровни образуются группами функций операционной системы - файловая система, управление процессами и устройствами и т.п. Каждый уровень может взаимодействовать только со своим непосредственным соседом - выше- или нижележащим уровнем. Прикладные программы или модули самой операционной системы передают запросы вверх и вниз по этим уровням. Они хорошо реализуются, но сложны в разработке так как трудно рассчитать порядок слоев и что к какому слою относится, системы менее эффективны чем монолитные ОС. Ядро может состоять из следующих слоев:
· средства аппаратной поддержки (система прерываний, средства переключения контекстов процессов, средства поддержки привилегированного режима, средства защиты областей памяти и т. д.);
· машинно-зависимые компоненты ОС; в идеале этот слой полностью экранирует вышележащие слои ядра от особенностей аппаратуры (пример – слой HAL ОС Windows NT);
· базовые механизмы ядра, этот слой выполняет наиболее примитивные операции ядра, реализует решения о распределении ресурсов, принятые на более высоком уровне;
· менеджеры ресурсов; слой состоит из мощных функциональных модулей, реализующих стратегические задачи по управлению основными ресурсами ОС;
· интерфейс системных вызовов является самым верхним слоем ядра и взаимодействует непосредственно с приложениями и системными утилитами, образуя прикладной программный интерфейс ОС. в начало
12.
Микроядерная
архитектура ОС
В микроядерной архитектуре в привилегированном режиме остается работать только очень небольшая часть ОС, называемая микроядром. Микроядро защищено от остальных частей ОС и приложений. В состав микроядра обычно входят машинно-зависимые модули, а также модули, выполняющие базовые функции ядра по управлению процессами, обработке прерываний, управлению виртуальной памятью, пересылке сообщений и управлению устройствами ввода/вывода, которые практически невозможно выполнить в пользовательском режиме. Все остальные функции ядра оформляются в виде приложений, работающих в пользовательском режиме, которые теперь называются серверами ОС. Клиент, которым может быть либо другой компонент ОС, либо прикладная программа, запрашивает сервис, посылая сообщение на сервер. Микроядро, работающее в привилегированном режиме, доставляет сообщение нужному серверу, сервер выполняет операцию, после чего ядро возвращает результаты клиенту с помощью другого сообщения Поддержка этого механизма является одной из главных задач микроядра.
Основное достоинство микроядерной архитектуры – высокая степень модульности ядра ОС. Это существенно упрощает добавление в него новых компонентов. Микроядерная архитектура повышает надежность системы, поскольку ошибка на уровне непривилегированной программы менее опасна, чем отказ на уровне режима ядра. В то же время, микроядерная архитектура существенно снижает производительность операционной системы.
Одна из проблем, возникающих при разработке микроядерной ОС – какие функции включать в микроядро, а какие выносить в пользовательское пространство. В идеальном случае микроядро может состоять только из средств передачи сообщений и аппаратно-зависимых модулей (так называемая модель экзоядра). Для повышения производительности ОС в состав микроядра могут входить и другие часто используемые функции. Минус микроядерной архитектуры - снижение производительности. Приложение обращается к микроядру, оно обращается к серверу, потом снова к микроядру. в начало
13.
Многослойная
модель ядра ОС
См. вторую часть вопроса 11. в начало
14.
Функции ОС по
управлению процессами
· распределяет процессорное время между несколькими одновременно выполняющимися в системе процессами;
· создает и уничтожает процессы;
· обеспечивает процессы необходимыми ресурсами;
· поддерживает синхронизацию процессов;
· реализует межпроцессное взаимодействие. в начало
15.
Процессы и потоки
Программа - статический объект на диске.
Процесс - контейнер для ресурсов и исходных кодов программ. С каждым процессом программа связывает её адресное пространство, которое содержит стек, данные, набор регистров.
Поток - системный объект, получающий процессорное время, в рамках потоков выполняются инструкции процессором. Каждый процесс должен иметь хотя бы один поток (если ОС поддерживает потоки). Потоки одного процесса делят между собой адресное пространство, глобальные переменные, открытые файлы, таймеры, семафоры, статическую информацию своего процесса.
Преимущества потоков:
· меньше затрат на создание по сравнению с процессами;
· возможность взаимодействия между собой в пределах одного процесса, не обращаясь к ОС;
· повышение производительности одной программы.
С каждым процессом связывается его адресное пространство. Адресное пространство процесса содержит саму программу, ее данные, стек программы.
В операционных системах, где существуют и процессы, и потоки, процесс рассматривается как заявка на потребление всех видов ресурсов, кроме одного – процессорного времени. Процессорное время выделяется потокам. В простейшем случае процесс состоит из одного потока.
Три события приводят к созданию процесса:
· загрузка системы;
· уже работающий процесс вызывает запрос на создание процесса;
· запрос пользователя на создание процесса.
Создать процесс означает:
· создать описатель процесса;
· загрузить коды и данные исполняемой программы процесса с диска в оперативную память;
· в многопоточной системе для каждого создаваемого процесса создать как минимум один поток выполнения.
Дескриптор содержит информацию, необходимую в течение всего жизненного цикла процесса, и где содержится информация о состоянии процесса, о расположении его в памяти и на диске, информация о приоритете и пр.
Контекст содержит информацию, которая необходима для возобновления процесса. в начало
16.
Состояния потока
За время своего существования в системе поток может многократно находиться в одном из трех состояний:
· выполнение – активное состояние, во время которого поток обладает всеми необходимыми ресурсами и непосредственно выполняется процессором;
· готовность – пассивное состояние, поток заблокирован в связи с внешними по отношению к нему обстоятельствами; в очередь готовых к выполнению попадает вновь созданный процесс;
· ожидание – пассивное состояние, находясь в котором поток заблокирован по своим внутренним причинам (ждет осуществления некоторого события, например, завершения операции ввода/вывода).
Возможные переходы между состояниями:
· Поток выбран на выполнение;
· Поток ожидает завершения ввода/вывода;
· Ввод/вывод завершен (событие произошло);
· Поток вытеснен.
В состоянии выполнения в
однопроцессорной системе может находиться не более одного потока, а в каждом из
состояний ожидания и готовности – несколько потоков. Эти потоки организуются в
очереди. в начало
17.
Планирование и
диспетчеризация потоков, моменты перепланировки
На протяжении существования процесса выполнение его потоков может быть многократно прервано и продолжено. Переход от одного потока к другому осуществляется в результате планирования и диспетчеризации.
Планирование включает в себя решение двух задач:
· определение момента времени для смены текущего активного потока;
· выбор для выполнения потока из очереди готовых потоков.
Планирование может быть динамическим (решения принимаются во время работы системы на основе анализа текущей ситуации) и статическим (решения приняты заранее, работа по расписанию).
Диспетчеризация заключается в реализации найденного в результате планирования решения, то есть в переключении процессора с одного потока на другой.
Диспетчеризация сводится к следующему:
· сохранение контекста текущего потока, который требуется сменить;
· загрузка контекста нового потока, выбранного в результате планирования;
· запуск нового потока на выполнение.
Ситуации, когда необходимо планирование:
1) Время, отведенное активной задаче на выполнение, закончилось. Планировщик переводит задачу в состояние готовности и выполняет перепланирование.
2) Активная задача выполнила системный вызов, связанный с запросом на ввод/вывод или на доступ к ресурсу, который в настоящий момент занят. Планировщик переводит задачу в состояние ожидания и выполняет перепланирование.
3) Активная задача выполнила системный вызов, связанный с освобождением ресурса. Если есть, то она переводится из состояния ожидания в состояние готовность. Проверяются приоритеты готовых к выполнению задач.
4) Завершение периферийным устройством операции ввода/вывода переводит соответствующую задачу в очередь готовых, и выполняется планирование.
5) Внутреннее прерывание сигнализирует об ошибке, которая произошла в результате выполнения активной задачи. Планировщик снимает задачу и выполняет перепланирование. в начало
18.
Алгоритм
планирования, основанный на квантовании
В основе многих вытесняющих алгоритмов планирования лежит концепция квантования. В соответствии с этой концепцией каждому потоку поочередно для выполнения предоставляется ограниченный непрерывный период процессорного времени — квант. Смена активного потока происходит, если:
· поток завершился и покинул систему;
· произошла ошибка;
· поток перешел в состояние ожидания;
· исчерпан квант процессорного времени, отведенный данному потоку.
Поток, который исчерпал свой квант, переводится в состояние готовности и ожидает, когда ему будет предоставлен новый квант процессорного времени, а на выполнение в соответствии с определенным правилом выбирается новый поток из очереди готовых.
Кванты, выделяемые потокам, могут быть одинаковыми для всех потоков или различными. Чем больше квант, тем выше вероятность того, что потоки завершатся в результате первого же цикла выполнения, и тем менее явной становится зависимость времени ожидания потоков от их времени выполнения. При достаточно большом кванте алгоритм квантования вырождается в алгоритм последовательной обработки, присущий однопрограммным системам, при котором время ожидания задачи в очереди вообще никак не зависит от ее длительности. в начало
19.
Приоритетное планирование
Приоритетное обслуживание предполагает наличие у потоков некоторой изначально известной характеристики — приоритета, на основании которой определяется порядок их выполнения. Приоритет — это число, характеризующее степень привилегированности потока при использовании ресурсов вычислительной машины, в частности процессорного времени: чем выше приоритет, тем выше привилегии, тем меньше времени будет проводить поток в очередях. Приоритет может выражаться целым или дробным, положительным или отрицательным значением.
В большинстве операционных систем, поддерживающих потоки, приоритет потока непосредственно связан с приоритетом процесса, в рамках которого выполняется данный поток. Приоритет процесса назначается операционной системой при его создании.
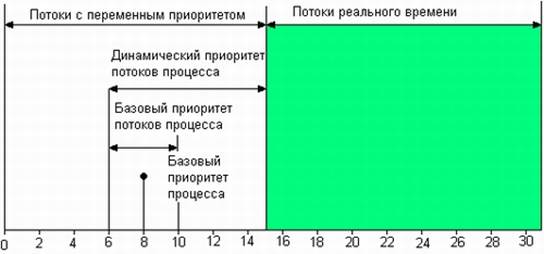
Рисунок 2. Приоритеты потоков в Windows NT
Существуют две разновидности приоритетного планирования: обслуживание с относительными приоритетами и обслуживание с абсолютными приоритетами.
В обоих случаях выбор потока на выполнение из очереди готовых осуществляется одинаково: выбирается поток, имеющий наивысший приоритет. Однако проблема определения момента смены активного потока решается по-разному. В системах с относительными приоритетами активный поток выполняется до тех пор, пока он сам не покинет процессор, перейдя в состояние ожидания (или же произойдет ошибка, или поток завершится).
В системах с абсолютными приоритетами выполнение активного потока прерывается кроме указанных выше причин, еще при одном условии: если в очереди готовых потоков появился поток, приоритет которого выше приоритета активного потока. В этом случае прерванный поток переходит в состояние готовности.
Во многих операционных системах алгоритмы планирования построены с использованием как концепции квантования, так и приоритетов. Например, в основе планирования лежит квантование, но величина кванта и/или порядок выбора потока из очереди готовых определяется приоритетами потоков. Именно так реализовано планирование в системе Windows NT, в которой квантование сочетается с динамическими абсолютными приоритетами. На выполнение выбирается готовый поток с наивысшим приоритетом. Ему выделяется квант времени. Если во время выполнения в очереди готовых появляется поток с более высоким приоритетом, то он вытесняет выполняемый поток. Вытесненный поток возвращается в очередь готовых, причем он становится впереди всех остальных потоков имеющих такой же приоритет. в начало
20.
Алгоритмы
планирования ОС пакетной обработки: «первым пришел – первым обслужен»,
«кратчайшая задача – первая», «наименьшее оставшееся время выполнения»
В таких ОС критерием эффективности служит максимальная загрузка аппаратуры.
Алгоритмы планирования:
· FIFO. Процессам предоставляется доступ к процессору в том порядке, в котором они его запрашивают. Достоинства: простота реализации. Недостатки: если есть один процесс, ограниченный возможностями процессора, то они замедлят работу процесса.
· Кратчайшая задача - первая. Нужно знать время выполнения задачи! Критерий - минимальное среднее оборотное время. Оборотное время - время, прошедшее от начала выполнения до получения результата.
· Наименьшее оставшееся время выполнения. Это версия предыдущего алгоритма с переключениями. В соответствии с этим алгоритмом планировщик каждый раз выбирает процесс с наименьшим оставшимся временем выполнения. В этом случае также необходимо заранее знать время выполнения задач. Когда поступает новая задача, ее полное время выполнения сравнивается с оставшимся временем выполнения текущей задачи. Если время выполнения новой задачи меньше, текущий процесс приостанавливается и управление передается новой задаче. Эта схема позволяет быстро обслуживать короткие запросы. в начало
21.
Алгоритмы
планирования в интерактивных ОС: циклическое, приоритетное, гарантированное,
лотерейное, справедливое планирование
Цель планирования в системах разделения времени - повышение удобства и эффективности работы пользователя. В системах разделения времени пользователям (или одному пользователю) предоставляется возможность интерактивной работы сразу с несколькими приложениями. ОС принудительно периодически приостанавливает приложения, не дожидаясь, когда они добровольно освободят процессор. Всем приложениям попеременно предоставляется квант процессорного времени, таким образом, что пользователи, запустившие программы на выполнение, получают возможность поддерживать с ними диалог.
Циклическое планирование. Самый простой алгоритм планирования и часто используемый. Каждому процессу предоставляется квант времени процессора. Когда квант заканчивается, процесс переводится планировщиком в конец очереди, а управление передается следующему за ним процессу.
Преимущества:
· простота;
· справедливость (как в очереди покупателей, каждому только по килограмму).
Недостатки:
· слишком малый квант времени (по сравнению с временем переключения контекстов) приводит к частому переключению процессов и снижению производительности;
· слишком большой квант может привести к увеличению времени ответа на интерактивный запрос.
Приоритетное планирование. Каждому процессу присваивается приоритет, и управление передается процессу с самым высоким приоритетом. Обычно процессы объединяют по приоритетам в группы, и применяют приоритетное планирование среди групп, а внутри группы используют циклическое планирование.
Гарантированное
планирование.
ОС гарантирует существующим потокам, что они получат гарантированную
справедливую часть процессорного времени. n потоков, 1/n
частей
процессорного времени каждому. Стс должна вести учет времени, получаемого
каждым потоком, в момент перепланировки вычисляется отношение фактически
получаемого воремени к времени гарантированному. На выполнение выбирается тот
поток, у которого это отношение наименьшее.
Лотерейное планирование. Процессам раздаются "лотерейные билеты", дающие право доступа к ресурсам. Планировщик может выбрать любой билет случайным образом. Чем больше билетов у процесса, тем больше у него шансов захватить ресурс. Взаимодействующие процессы могут при необходимости обмениваться билетами.
Справедливое планирование. Учитывается принадлежность процессов пользователям, в отличие от других алгоритмов. Процессорное время делится между пользователями. в начало
22.
Алгоритм
планирования Windows NT
Алгоритм планирования нитей в Windows NT объединяет в себе обе базовых концепции - квантование и приоритеты. Как и во всех других алгоритмах, основанных на квантовании, каждой нити назначается квант, в течение которого она может выполняться. Нить освобождает процессор, если:
- блокируется, уходя в состояние ожидания;
- завершается;
- исчерпан квант;
· в очереди готовых появляется более приоритетная нить.
Использование динамических приоритетов, изменяющихся во времени, позволяет реализовать адаптивное планирование, при котором не дискриминируются интерактивные задачи, часто выполняющие операции ввода-вывода и недоиспользующие выделенные им кванты. Если нить полностью исчерпала свой квант, то ее приоритет понижается на некоторую величину. В то же время приоритет нитей, которые перешли в состояние ожидания, не использовав полностью выделенный им квант, повышается. Приоритет не изменяется, если нить вытеснена более приоритетной нитью.
Для того, чтобы обеспечить хорошее время реакции системы, алгоритм планирования использует наряду с квантованием концепцию абсолютных приоритетов. В соответствии с этой концепцией при появлении в очереди готовых нитей такой, у которой приоритет выше, чем у выполняющейся в данный момент, происходит смена активной нити на нить с самым высоким приоритетом. в начало
23.
Планирование в ОС
реального времени
ОС реального времени предназначены для управления различными техническими объектами или технологическими процессами. В таких системах мультипрограммная смесь обычно представляет собой фиксированный набор заранее разработанных программ, а выбор программы на выполнение осуществляется по прерываниям (исходя из состояния управляемого объекта) или в соответствии с расписанием плановых работ. Критерий эффективности работы ОС реального времени – способность системы выдерживать заранее заданные интервалы времени между запуском программы и получением результата (реактивность системы).
Системы реального времени делятся на:
· жесткие - несоблюдение временных ограничений приводит к катастрофическим последствиям; в таких системах время завершения выполнения каждой из критических задач должно быть гарантировано для всех возможных сценариев работы системы;
· гибкие - нарушения временного графика нежелательны, но допустимы, это позволяет использовать менее затратные способы планирования.
Внешние события, на которые система должна реагировать, делятся:
· периодические – начиная с момента первоначального запроса все будущие моменты возникновения задачи можно определить заранее;
· спорадические - моменты возникновения запросов заранее неизвестны.
Планировщик бывает:
· Статический: до запуска системы составляется расписание. Все решения сделаны заранее, во время выполнения реализуется это расписание;
· Динамический: работает после запуска системы, не имея предварительных сведений. в начало
24.
Синхронизация
процессов и потоков: цели и средства синхронизации
Существует достаточно обширный класс средств операционной системы, с помощью которых обеспечивается взаимная синхронизация процессов и потоков. Потребность в синхронизации потоков возникает только в мультипрограммной операционной системе и связана с совместным использованием аппаратных и информационных ресурсов вычислительной системы. Синхронизация необходима для исключения гонок и тупиков при обмене данными между потоками, разделении данных, при доступе к процессору и устройствам ввода-вывода.
Во многих операционных системах эти средства называются средствами межпроцессного взаимодействия — Inter Process Communications (IPC), что отражает историческую первичность понятия «процесс» по отношению к понятию «поток».
Выполнение потока в мультипрограммной среде всегда имеет асинхронный характер. Очень сложно с полной определенностью сказать, на каком этапе выполнения будет находиться процесс в определенный момент времени. Даже в однопрограммном режиме не всегда можно точно оценить время выполнения задачи. Это время во многих случаях существенно зависит от значения исходных данных, которые влияют на количество циклов, направления разветвления программы, время выполнения операций ввода-вывода и т. п. Так как исходные данные в разные моменты запуска задачи могут быть разными, то и время выполнения отдельных этапов и задачи в целом является весьма неопределенной величиной.
Еще более неопределенным является время выполнения программы в мультипрограммной системе. Моменты прерывания потоков, время нахождения их в очередях к разделяемым ресурсам, порядок выбора потоков для выполнения — все эти события являются результатом стечения многих обстоятельств и могут быть интерпретированы как случайные. В лучшем случае можно оценить вероятностные характеристики вычислительного процесса, например вероятность его завершения за данный период времени.
Любое взаимодействие процессов или потоков связано с их синхронизацией, которая заключается в согласовании их скоростей путем приостановки потока до наступления некоторого события и последующей его активизации при наступлении этого события. Синхронизация лежит в основе любого взаимодействия потоков, связано ли это взаимодействие с разделением ресурсов или с обменом данными. Например, поток-получатель должен обращаться за данными только после того, как они помещены в буфер потоком-отправителем. Если же поток-получатель обратился к данным до момента их поступления в буфер, то он должен быть приостановлен.
При совместном использовании аппаратных ресурсов синхронизация также совершенно необходима. Когда, например, активному потоку требуется доступ к последовательному порту, а с этим портом в монопольном режиме работает другой поток, находящийся в данный момент в состоянии ожидания, то ОС приостанавливает активный поток и не активизирует его до тех пор, пока нужный ему порт не освободится. Часто нужна также синхронизация с событиями, внешними по отношению к вычислительной системе, например реакции на нажатие комбинации клавиш Ctrl+C.
Ежесекундно в системе происходят сотни событий, связанных с распределением и освобождением ресурсов, и ОС должна иметь надежные и производительные средства, которые бы позволяли ей синхронизировать потоки с происходящими в системе событиями.
Для синхронизации потоков прикладных программ программист может использовать как собственные средства и приемы синхронизации, так и средства операционной системы. Например, два потока одного прикладного процесса могут координировать свою работу с помощью доступной для них обоих глобальной логической переменной, которая устанавливается в единицу при осуществлении некоторого события, например выработки одним потоком данных, нужных для продолжения работы другого. Однако во многих случаях более эффективными или даже единственно возможными являются средства синхронизации, предоставляемые операционной системой в форме системных вызовов. Так, потоки, принадлежащие разным процессам, не имеют возможности вмешиваться каким- либо образом в работу друг друга. Без посредничества операционной системы они не могут приостановить друг друга или оповестить о произошедшем событии. Средства синхронизации используются операционной системой не только для синхронизации прикладных процессов, но и для ее внутренних нужд.
Обычно разработчики операционных систем предоставляют в распоряжение прикладных и системных программистов широкий спектр средств синхронизации. Эти средства могут образовывать иерархию, когда на основе более простых средств строятся более сложные, а также быть функционально специализированными, например средства для синхронизации потоков одного процесса, средства для синхронизации потоков разных процессов при обмене данными и т. д. Часто функциональные возможности разных системных вызовов синхронизации перекрываются, так что для решения одной задачи программист может воспользоваться несколькими вызовами в зависимости от своих личных предпочтений. в начало
25.
Ситуация
состязаний (гонки). Способы предотвращения.
Состязания – ситуация, когда два или более потоков обрабатывают разделяемые данные и конечный результат зависит от соотношения скоростей потоков.
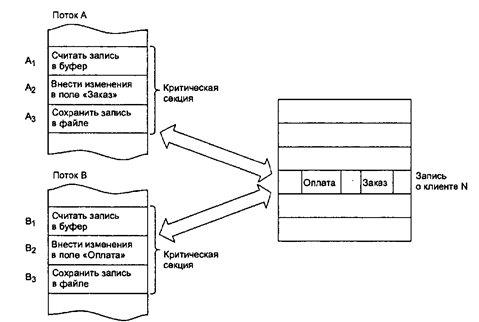
Рисунок 3. Возникновение гонок при доступе к разделяемым
ресурсам
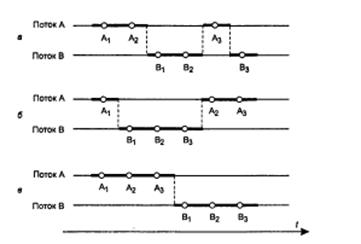
Рисунок 4. Влияние относительных скоростей потоков на результат
решения задачи
Важным понятием синхронизации потоков является понятие «критической секции» программы. Критическая секция — это часть программы, результат выполнения которой может непредсказуемо меняться, если переменные, относящиеся к этой части программы, изменяются другими потоками в то время, когда выполнение этой части еще не завершено. Критическая секция всегда определяется по отношению к определенным критическим данным, при несогласованном изменении которых могут возникнуть нежелательные эффекты. Во всех потоках, работающих с критическими данными, должна быть определена критическая секция. Заметим, что в разных потоках критическая секция состоит в общем случае из разных последовательностей команд. Чтобы исключить эффект гонок по отношению к критическим данным, необходимо обеспечить, чтобы в каждый момент времени в критической секции, связанной с этими данными, находился только один поток. При этом неважно, находится этот поток в активном или в приостановленном состоянии. Этот прием называют взаимным исключением. Операционная система использует разные способы реализации взаимного исключения. Некоторые способы пригодны для взаимного исключения при вхождении в критическую секцию только потоков одного процесса, в то время как другие могут обеспечить взаимное исключение и для потоков разных процессов. в начало
26.
Способы
реализации взаимных исключений: блокирующие переменные, критические секции,
семафоры Дейкстры
Блокирующие переменные
Для синхронизации потоков одного процесса прикладной программист может использовать глобальные блокирующие переменные. С этими переменными, к которым все потоки процесса имеют прямой доступ, программист работает, не обращаясь к системным вызовам ОС.
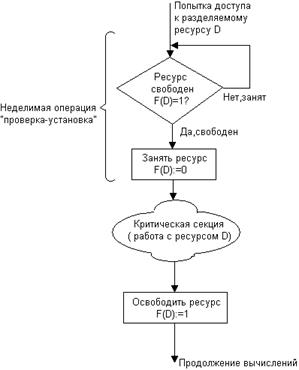
Рисунок 5. Реализация критической секции с использованием
блокирующих переменных
Каждому набору критических данных ставится в соответствие двоичная переменная, которой поток присваивает значение 0, когда он входит в критическую секцию, и значение 1, когда он ее покидает. На рисунке показан фрагмент алгоритма потока, использующего для реализации взаимного исключения доступа к критическим данным D блокирующую переменную F(D). Перед входом в критическую секцию поток проверяет, не работает ли уже какой-нибудь поток с данными D. Если переменная F(D) установлена в 0, то данные заняты и проверка циклически повторяется. Если же данные свободны (F(D) = 1), то значение переменной F(D) устанавливается в 0 и поток входит в критическую секцию. После того как поток выполнит все действия с данными О, значение переменной F(D) снова устанавливается равным 1.
Нельзя прерывать поток между выполнением операций проверки и установки блокирующей переменной. Во избежание таких ситуаций в системе команд многих компьютеров предусмотрена единая, неделимая команда анализа и присвоения значения логической переменной (например, команды ВТС, BTR и ВТ5 процессора Pentium). При отсутствии такой команды в процессоре соответствующие действия должны реализовываться специальными системными примитивами, которые бы запрещали прерывания на протяжении всей операции проверки и установки.
Критические секции
Реализация взаимного исключения описанным выше способом имеет существенный недостаток: в течение времени, когда один поток находится в критической секции, другой поток, которому требуется тот же ресурс, получив доступ к процессору, будет непрерывно опрашивать блокирующую переменную, бесполезно тратя выделяемое ему процессорное время, которое могло бы быть использовано для выполнения какого-нибудь другого потока. Для устранения этого недостатка во многих ОС предусматриваются специальные системные вызовы для работы с критическими секциями.
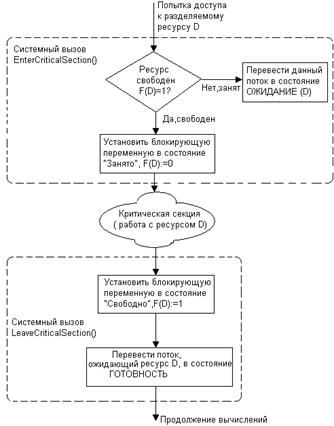
Рисунок 6. Реализация взаимного исключения с использованием
системных функций входа в критическую секцию и выхода из нее
На рисунке
показан бред. Не понимаю, зачем нужна какая-то блокирующая переменная при использовании
вызовов *CriticalSection.
Семафоры
Обобщением блокирующих переменных являются так называемые семафоры Дийкстры. Вместо двоичных переменных Дийкстра предложил использовать переменные, которые могут принимать целые неотрицательные значения. Такие переменные, используемые для синхронизации вычислительных процессов, получили название семафоров.
Для работы с семафорами вводятся два примитива, традиционно обозначаемых Р и V. Пусть переменная S представляет собой семафор. Тогда действия V(S) и P(S) определяются следующим образом.
V(S): переменная S увеличивается на 1 единым действием. Выборка, наращивание и запоминание не могут быть прерваны. К переменной S нет доступа другим потокам во время выполнения этой операции.
P(S): уменьшение S на 1, если это возможно. Если S=0 и невозможно уменьшить S, оставаясь в области целых неотрицательных значений, то в этом случае поток, вызывающий операцию Р, ждет, пока это уменьшение станет возможным. Успешная проверка и уменьшение также являются неделимой операцией.
Никакие прерывания во время выполнения примитивов V и Р недопустимы.
В частном случае, когда семафор S может принимать только значения 0 и 1, он превращается в блокирующую переменную, которую по этой причине часто называют двоичным семафором (он же наш любимый мьютекс). Операция Р заключает в себе потенциальную возможность перехода потока, который ее выполняет, в состояние ожидания, в то время как операция V может при некоторых обстоятельствах активизировать другой поток, приостановленный операцией Р.
Для примера можно привести задачу производителя и потребителя. Имеется некий буфер размера N. Используя 2 семафора - один блокирует работу источника, если буфер переполнен, второй блокирует работу потребителя, если в буфере пусто. Первый должен быть инициализирован N, второй 0.
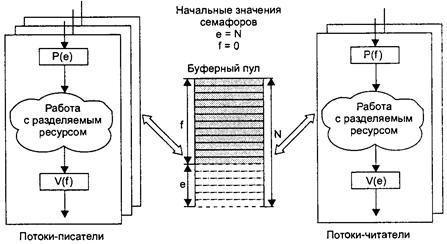
Рисунок 7. Использование семафоров для синхронизации потоков
в начало
27.
Взаимные
блокировки. Условия, необходимые для возникновения тупика
Тупиковые ситуации надо отличать от простых очередей: хотя те и другие возникают при совместном использовании ресурсов и внешне выглядят похоже: поток приостанавливается и ждет освобождения ресурса. Однако очередь — это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Очередь появляется тогда, когда ресурс недоступен в данный момент, но освободится через некоторое время, позволив потоку продолжить выполнение. Тупик же, что видно из его названия, является неразрешимой ситуацией. Необходимым условием возникновения тупика является потребность потока сразу в нескольких ресурсах.
· Процессы требуют предоставления им права монопольного управления ресурсами, которые им предоставляются (условие взаимоисключения);
· Процессы удерживают за собой ресурсы, выделенные им, в то же время ожидают выделения дополнительных ресурсов (условие ожидания ресурсов);
· Ресурсы нельзя отобрать у процесса, удерживающего их, пока эти ресурсы не будут использованы для завершения работы (условия неперераспределенности);
· Существует кольцевая цепь процессов, в которой каждый процесс удерживает за собой один или более ресурсов, требующихся следующему процессу цепи (условие кругового ожидания). в начало
28.
Обнаружение
взаимоблокировки при наличии одного ресурса каждого типа
Методы борьбы с блокировками:
· Метод страуса. Если мы будем игнорировать проблему, то она возможно не принесет вреда. Применяется, когда потери от взаимоблокировок незначительны. Популярные ОС обычно так и делают.
· Обнаружение и исправление после возникновения блокировки (если существуют методы)
· Динамическое избежание взаимоблокировок (ОС не допускает их возникновения)
· Предотвращение с помощью опровержения первого условия необходимости (не давать ресурсы монопольно)
Обнаружение взаимоблокировки при наличии одного ресурса каждого типа:
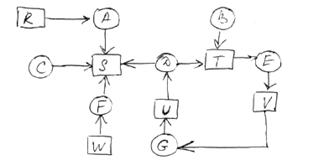
Рисунок 8. Система из 7ми процессов и 6ти ресурсов
1) Начальное условие: задаем L - пустой список. Ребра не маркированы
2) Текущий узел добавляем в конец списка L и проверяем количество появлений узла в списке. Если есть повторы, то есть цикл, то алгоритм завершается
3) Для заданного узла смотрим, выходит ли у него хоть 1 немаркированное ребро. Да - переход к 4, нет - переход к 5
4) Случайным образом выбираем немаркированное ребро и отмечаем его. По нему переходим к новому текущему узлу и возвращаемся к 2.
5) Удаляем последний узел из списка и возвращаемся к следующему узлу. Обозначаем его текущим и возвращаемся к 2. Если это первоначальный узел, значит граф не содержит циклов и алгоритм завершится. в начало
29.
Обнаружение
взаимоблокировок при наличии нескольких ресурсов каждого типа
В системе имеем наборы однотипный ресурсов (одного класса). Классов ресурсов m. Процессов n. Для обнаружения тупиков поддерживается несколько структур.
·
E
- вектор существующих ресурсов
·
С - матрица текущего распределения
Элемент Cij - показывает, сколько экземпляров j-го класса ресурсов принадлежит i-му процессу.
· R - матрица запросов, показывает, сколько еще экземпляров ресурсов нужно процессу для благополучного завершения (j-го ресурса i-му процессу)
· A - вектор доступных ресурсов.
Алгоритм:
1) Ищем немаркированный процесс Pi, для которого i-я строка матрицы R <=A (запросы меньше возможностей)
2) Если так, процесс найдет, прибавляем i-ю строку матрицы С к вектору А и возвращаемся к 1. Если таких процессов не существует, то алгоритм заканчивается (если все процессы промаркированы, то тупика нет) в начало
30.
Предотвращение
взаимоблокировки. Алгоритм банкира для одного вида ресурсов
Говорят, что состояние безопасно, если оно не находится в тупике и существует некоторый порядок планирования, при котором каждому процессу можно работать до завершения даже если все процессы захотят немедленно получить свое максимальное количество ресурсов.
Алгоритм банкира для 1 вида ресурсов (основан на избегании опасных состояний):
Алгоритм рассматривает запросы на предоставления ресурсов по мере их поступления. Каждый раз проверяет, приведет ли удовлетворение запроса к безопасному состоянию. Если да - запрос удовлетворяется, если нет - откладывается на более позднее время. в начало
31.
Предотвращение
взаимоблокировки. Алгоритм банкира для нескольких видов ресурсов
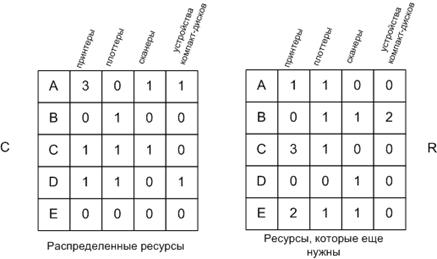
Рассмотрим систему:
Вектора:
E=(6342) - существующие ресурсы, P=(5322) - занятые ресурсы, A=(1020) - доступные ресурсы.
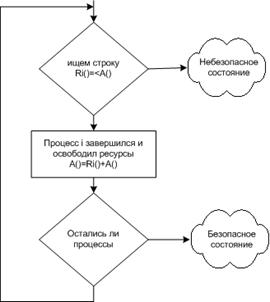
Рисунок 9. Алгоритм банкира для несколько видов ресурсов
Если состояние безопасное, то ресурс выделить можно, если нет - нельзя. На практике эти алгоритмы сложно реализовать. в начало
32.
Синхронизирующие
объекты ОС: системные семафоры, мьютексы, события, сигналы, ждущие таймеры, мониторы
В случае синхронизации потоков разных процессов операционная система должна предоставлять потокам системные объекты синхронизации, которые были бы видны для всех потоков, даже если они принадлежат разным процессам и работают в разных адресных пространствах. Примерами таких синхронизирующих объектов ОС являются системные семафоры, мьютексы, события, таймеры и другие.
Все синхронизирующие объекты могут находиться в двух состояниях:
· сигнальном
· несигнальном (свободном).
Мьютексы
Объекты-взаимоисключения (мьютексы, mutex - от MUTual EXclusion) позволяют координировать взаимное исключение доступа к разделяемому ресурсу. Сигнальное состояние объекта (т.е. состояние "установлен") соответствует моменту времени, когда объект не принадлежит ни одному потоку и его можно "захватить". Предположим, что мьютекс находится в сигнальном состоянии, в этом случае поток тут же становится его владельцем, устанавливая его в несигнальное состояние, и входит в критическую секцию. После того как поток выполнил работу с критическими данными, он «отдает» мьютекс, устанавливая его в сигнальное состояние. Если какой-либо поток ожидает его освобождения, то он становится следующим владельцем этого мьютекса, одновременно мьютекс переходит в несигнальное состояние.
Системные семафоры
Существует еще один метод синхронизации потоков, в котором используются семафорные объекты API. В семафорах применен принцип действия мьютексов, но с добавлением одной существенной детали. В них заложена возможность подсчета ресурсов, что позволяет заранее определенному числу потоков одновременно войти в синхронизуемый участок кода. Для создания семафора используется функция CreateSemaphore.
События
События используются в качестве сигналов о завершении какой-либо операции. В отличие от мьютексов, они не принадлежат ни одному потоку. Объект-событие обычно используется не для доступа к данным, а для того, чтобы оповестить другие потоки о том, что некоторые действия завершены. Пусть, например, в некотором приложении работа организована таким образом, что один поток читает данные из файла в буфер памяти, а другие потоки обрабатывают эти данные, затем первый поток считывает новую порцию данных, а другие потоки снова ее обрабатывают и так далее. В начале работы первый поток устанавливает объект-событие в несигнальное состояние. Все остальные потоки выполнили вызов Wait(X), где X — указатель события, и находятся в приостановленном состоянии, ожидая наступления этого события. Как только буфер заполняется, первый поток сообщает об этом операционной системе, выполняя вызов Set(X). Операционная система просматривает очередь ожидающих потоков и активизирует все потоки, которые ждут этого события.
Ждущие таймеры
Ждущий таймер (waitable timer) представляет собой новый тип объектов синхронизации, поддерживаемый в Windows NT версии 4.0 и выше. Это полноценный объект синхронизации, который может использоваться для организации задержки в одном или нескольких приложениях. Ждущий таймер работает в трех режимах. В режиме «ручного сброса» таймер переходит в установленное состояние при истечении заданной задержки и остается установленным до тех пор, пока функция SetWaitableTimer не задаст новую задержку. В режиме «автоматического сброса» таймер переходит в установленное состояние при истечении заданной задержки и остается установленным до первого успешного вызова функции ожидания. Каждый раз при истечении времени задержки разрешается выполнение лишь одной нити. Наконец, ждущий таймер может выполнять функции интервального таймера, который перезапускается с заданной задержкой после каждого срабатывания объекта.
Главная особенность, отличающая ждущие таймеры от системных, — то, что ждущие таймеры могут совместно использоваться несколькими приложениями. Процессы получают дескрипторы ждущих таймеров так же, как они получают дескрипторы мьютексов: дублированием, наследованием или открытием по имени.
Мониторы Хоара
Монитор – это набор процедур и информационных структур, которыми процессы пользуются в режиме разделения, причем в фиксированный момент времени им может пользоваться только один процесс. Отличительная особенность монитора в том, что в его распоряжении находится некоторая специальная информация, предназначенная для общего пользования, но доступ к ней можно получить только при обращении к этому монитору. Монитор не является процессом, это пассивный объект, который приходит в активное состояние только тогда, когда какой-то объект обращается к нему за услугами. в начало
33.
Организация
обмена данными между процессами (каналы, разделяемая память, почтовые ящики,
сокеты)
Операционная система, имея доступ ко всем областям памяти, играет роль посредника в информационном обмене прикладных потоков. При необходимости в обмене данными поток обращается с запросом к ОС. ОС, пользуясь своими привилегиями, создает различные системные средства связи. Многие из средств межпроцессного обмена данными выполняют также и функции синхронизации: в том случае, когда данные для процесса-получателя отсутствуют, последний переводится в состояние ожидания средствами ОС, а при поступлении данных от процесса-отправителя процесс-получатель активизируется.
Разделяемая память представляет собой сегмент физической памяти, отображенной в виртуальное адресное пространство двух или более процессов. Одно из преимуществ файлов, отображаемых в память, заключается в том, что их легко использовать совместно. Присвоение имени объекту «отображение файла» делает возможным совместное использование файла несколькими процессами. В этом случае его содержимое отображено на совместно используемую физическую память.
Канал (pipe, конвейер) - псевдофайл, в который один процесс пишет, а другой читает;
Сокеты - поддерживаемый ядром механизм, скрывающий особенности среды и позволяющий единообразно взаимодействовать процессам, как на одном компьютере, так и в сети;
Почтовые ящики (только в Windows), однонаправленные, возможность широковещательной рассылки;
Почтовые ящики обеспечивают только однонаправленные соединения. Каждый процесс, который создает почтовый ящик, является «сервером почтовых ящиков». Другие процессы, называемые «клиентами почтовых ящиков», посылают сообщения серверу, записывая их в почтовый ящик. Входящие сообщения всегда дописываются в почтовый ящик и сохраняются до тех пор, пока сервер их не прочтет. Каждый процесс может одновременно быть и сервером и клиентом почтовых ящиков, создавая, таким образом, двунаправленные коммуникации между процессами.
Клиент может посылать сообщения на почтовый ящик, расположенный на том же компьютере, на компьютере в сети, или на все почтовые ящики с одним именем всем компьютерам выбранного домена. Почтовые ящики предлагают легкий путь для обмена короткими сообщениями, позволяя при этом вести передачу и по локальной сети, в том числе и по всему домену.
Почтовый ящик является псевдофайлом находящимся в памяти и необходимо использовать стандартные функции для работы с файлами, чтобы получить доступ к нему. Все почтовые ящики являются локальными по отношению к создавшему их процессу. Процесс не может создать удаленный почтовый ящик.
Вызов удаленной процедуры, процесс А может вызвать процедуру в процессе В, и получить обратно данные. в начало
34.
Функции ОС по
управлению памятью
- отслеживание свободной и занятой памяти;
- выделение памяти процессам и освобождение памяти по завершении процессов;
- организация виртуальной памяти;
- настройка адресов программы на конкретную область физической памяти;
- динамическое распределение памяти;
- дефрагментация памяти;
- защита памяти. в начало
35.
Виртуальная
память
На разных этапах жизненного цикла программы используются различные типы адресов:
· символьные имена присваивает пользователь при написании на алгоритмическом языке или ассемблере;
· виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во время трансляции в общем случае неизвестно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные адреса, считая, что начальным адресом будет нулевой адрес;
· физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды.
Совокупность виртуальных адресов называется виртуальным адресным пространством. Различают максимально возможное виртуальное адресное пространство (определяется архитектурой компьютера) и назначенное (выделенное) процессу виртуальное адресное пространство (фактически нужные процессу адреса, первоначально назначается транслятором, размер его может быть изменен во время выполнения). Обычно виртуальное адресное пространство процесса делится на две непрерывные части: системную и пользовательскую (по умолчанию в Windows 2000 эти части имеют одинаковый размер – по 2 Гбайт; пользовательская часть адресного пространства процесса располагается в диапазоне адресов 00000000-7FFFFFFF, системная – 80000000-FFFFFFFF).
Системная часть виртуальной памяти в ОС любого типа включает область, подвергаемую страничному вытеснению, и область, на которую страничное вытеснение не распространяется. В невытесняемой области размещаются модули, требующие быстрой реакции и /или постоянного присутствия в памяти, например диспетчер потоков. Остальные модули ОС подвергаются страничному вытеснению, как и пользовательские процессы.
В разных ОС используются разные способы структуризации виртуального адресного пространства. В одних ОС виртуальное адресное пространство процесса представлено в виде непрерывной линейной последовательности виртуальных адресов. Такую структуру делится на адресного пространства называют плоской. При этом виртуальным адресом является одно число, представляющее собой смещение от начала виртуального адресного пространства. Это линейный виртуальный адрес. В других ОС виртуальное адресное пространство части, называемые сегментами. В этом случае помимо линейного адреса может быть использован виртуальный адрес, представляющий собой пару чисел (m,n), где n определяет сегмент, а m – смещение внутри сегмента. Существуют и более сложные способы организации виртуального адресного пространства.
Задачей ОС является отображение индивидуальных адресных пространств всех одновременно выполняющихся процессов на общую физическую память.
В настоящее время типична ситуация, когда объем
виртуального адресного пространства превышает доступный объем оперативной
памяти (максимальный размер физической памяти,
которую можно установить в компьютере определенной модели ограничивается разрядностью
адресной шины).
Существует два подхода к преобразованию виртуальных адресов в физические:
1) Пересчет виртуальных адресов в физические выполняется один раз для каждого процесса во время начальной загрузки программы в память. Эту операцию выполняет специальная системная программа – перемещающий загрузчик.
2) Программа загружается в память с неизмененными виртуальными адресами. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Это так называемое динамическое преобразование адресов.
Виртуализация оперативной памяти осуществляется совместно ОС и аппаратными средствами процессора и включает решение следующих задач:
· размещение данных в запоминающих устройствах разного типа, например часть кодов программы – в оперативной памяти, а часть – на диске;
· выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;
· перемещение по мере необходимости данных между памятью и диском;
· преобразование виртуальных адресов в физические.
Виртуализация памяти может быть осуществлена на основе двух различных подходов:
· свопинг (swapping) — образы процессов выгружаются на диск и возвращаются в оперативную память целиком;
· виртуальная память (virtual memory) — между оперативной памятью и диском перемещаются части (сегменты, страницы и т. п.) образов процессов.
Свопинг представляет собой частный случай виртуальной памяти и, следовательно, более простой в реализации способ совместного использования оперативной памяти и диска. Однако подкачке свойственна избыточность: когда ОС решает активизировать процесс, для его выполнения, как правило, не требуется загружать в оперативную память все его сегменты полностью — достаточно загрузить небольшую часть кодового сегмента с подлежащей выполнению инструкцией и частью сегментов данных, с которыми работает эта инструкция, а также отвести место под сегмент стека. Аналогично при освобождении памяти для загрузки нового процесса очень часто вовсе не требуется выгружать другой процесс на диск целиком, достаточно вытеснить на диск только часть его образа. Перемещение избыточной информации замедляет работу системы, а также приводит к неэффективному использованию памяти. Кроме того, системы, поддерживающие свопинг, имеют еще один очень существенный недостаток: они не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память. Именно из-за указанных недостатков свопинг как основной механизм управления памятью почти не используется в современных ОС. На смену ему пришел более совершенный механизм виртуальной памяти, который заключается в том, что при нехватке места в оперативной памяти на диск выгружаются только части образов процессов.
Ключевой проблемой виртуальной памяти, возникающей в результате многократного изменения местоположения в оперативной памяти образов процессов или их частей, является преобразование виртуальных адресов в физические. Решение этой проблемы, в свою очередь, зависит от того, какой способ структуризации виртуального адресного пространства принят в данной системе управления памятью. В настоящее время все множество реализаций виртуальной памяти может быть представлено тремя классами.
· Страничная виртуальная память организует перемещение данных между памятью и диском страницами — частями виртуального адресного пространства, фиксированного и сравнительно небольшого размера.
· Сегментная виртуальная память предусматривает перемещение данных сегментами — частями виртуального адресного пространства произвольного размера, полученными с учетом смыслового значения данных.
· Сегментно-страничная виртуальная память использует двухуровневое деление: виртуальное адресное пространство делится на сегменты, а затем сегменты делятся на страницы. Единицей перемещения данных здесь является страница. Этот способ управления памятью объединяет в себе элементы обоих предыдущих подходов.
Для временного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, которые во многих ОС по традиции продолжают называть областью, или файлом свопинга, хотя перемещение информации между оперативной памятью и диском осуществляется уже не в форме полного замещения одного процесса другим, а частями. Другое популярное название этой области — страничный файл (page file, или paging file). Текущий размер страничного файла является важным параметром, оказывающим влияние на возможности операционной системы: чем больше страничный файл, тем больше приложений может одновременно выполнять ОС (при фиксированном размере оперативной памяти). Однако необходимо понимать, что увеличение числа одновременно работающих приложений за счет увеличения размера страничного файла замедляет их работу, так как значительная часть времени при этом тратится на перекачку кодов и данных из оперативной памяти на диск и обратно. Размер страничного файла в современных ОС является настраиваемым параметром, который выбирается администратором системы для достижения компромисса между уровнем мультипрограммирования и быстродействием системы. в начало
36.
Алгоритмы
распределения памяти без использования внешних носителей (фиксированные, динамические,
перемещаемые разделы)
Распределение памяти фиксированными разделами. Память разбивается на несколько областей фиксированной величины, называемых разделами. Эта операция выполняется один раз, и после этого границы разделов не изменяются. Различные системы могут поддерживать либо общую очередь ко всем разделам (Рисунок 10, а)), либо отдельную очередь к каждому разделу (Рисунок 10, б)).
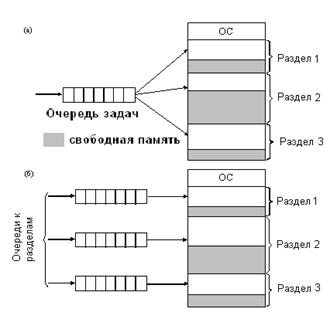
Рисунок
10.
Распределение памяти фиксированными
разделами
Подсистема управления памятью в этом случае выполняет следующие задачи:
· сравнивая размер программы, поступившей на выполнение, и свободных разделов, выбирает подходящий раздел;
· осуществляет загрузку программы и настройку адресов.
Достоинство:
· простота реализации;
Недостаток:
· жесткость. В каждом разделе может выполняться только одна программа, т. е. уровень мультипрограммирования заранее ограничен числом разделов, это приводит к неэффективному использованию памяти. С другой стороны, даже если общий объем оперативной памяти машины позволяет выполнить некоторую программу, разбиение памяти на разделы может не позволить сделать это.
Распределение памяти динамическими разделами. В начале работы вся память, отведенная для приложений, свободна. Память машины не делится заранее на разделы. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На Рисунок 11 показано состояние памяти в различные моменты времени при использовании динамического распределения.
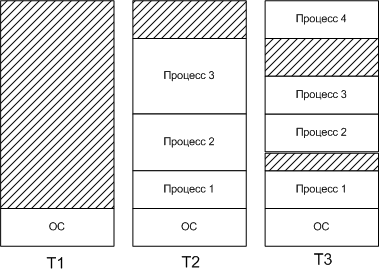
Рисунок
11.
Распределение памяти динамическими разделами
Задачами операционной системы при реализации данного метода управления памятью является:
· ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти;
· при поступлении новой задачи - анализ запроса, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи;
· загрузка задачи в выделенный ей раздел и корректировка таблиц свободных и занятых областей;
· после завершения задачи корректировка таблиц свободных и занятых областей.
Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов с помощью перемещающего загрузчика.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток - фрагментация памяти. Фрагментация - это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов), настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Перемещаемые разделы. Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область (Рисунок 12).
Рисунок
12.
Распределение памяти перемещаемыми разделами
В дополнение к функциям, которые выполняет ОС при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием". Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом. в начало
37.
Страничное
распределение памяти
Виртуальное адресное пространство процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами. Размер страницы выбирается кратным степени двойки. При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Для каждого процесса ОС создает таблицу страниц – информационную структуру, содержащую записи обо всех виртуальных страниц процесса.
Дескриптор страницы включает в себя следующую информацию:
· номер физической страницы, в которую загружена данная виртуальная страница;
· признак присутствия;
· признак модификации;
· признак обращения.
Признаки присутствия, модификации и обращения в большинстве моделей современных процессоров устанавливаются аппаратно. Таблицы страниц, также как и описываемые ими страницы, размещаются в оперативной памяти. Адрес таблицы страниц включается в контекст соответствующего процесса. При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса. При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти. В данной ситуации может быть использовано много разных критериев выбора, наиболее популярные из них следующие:
· дольше всего не использовавшаяся страница;
· первая попавшаяся страница;
· страница, к которой в последнее время было меньше всего обращений.
После того, как выбрана страница, которая должна покинуть оперативную память, анализируется ее признак модификации (из таблицы страниц). Если выталкиваемая страница с момента загрузки была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то соответствующая физическая страница просто объявляется свободной. в начало
38.
Таблицы страниц
для больших объемов памяти
Размер страницы влияет также на количество записей в таблицах страниц. Чем меньше страница, тем более объемными являются таблицы страниц процессов и тем больше места они занимают в памяти. Учитывая, что в современных процессорах максимальный объем виртуального адресного пространства процесса, как правило, не меньше 4 Гбайт, то при размере страницы 4 Кбайт и длине записи 4 байта для хранения таблицы страниц может потребоваться 4 Мбайт памяти.
Что придумали:
1) Многоуровневые таблицы страниц.
Достоинства:
· не надо иметь в памяти постоянно всю таблицу страниц, а только таблицу разделов;
Недостатки:
· дополнительный этап преобразования адреса
Для каждого раздела строится
собственная таблица страниц. Количество дескрипторов в таблице и их размер подбираются
такими, чтобы объем таблицы оказался равным объему страницы. Например, в процессоре
Pentium при размере страницы 4 Кбайт длина дескриптора страницы составляет 4
байта и количество записей в таблице страниц, помещающейся на страницу,
равняется соответственно 1024. Каждая таблица страниц описывается дескриптором,
структура которого полностью совпадает со структурой дескриптора обычной
страницы. Эти дескрипторы сведены в таблицу разделов, называемую также
каталогом страниц. Физический адрес таблицы разделов активного процесса
содержится в специальном регистре процессора и поэтому всегда известен
операционной системе. Страница, содержащая таблицу разделов, никогда не выгружается
из памяти, в противном случае работа виртуальной памяти была бы невозможна. 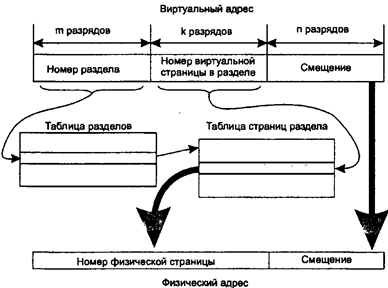
Рисунок 13. Схема преобразования виртуального адреса для
двухуровневой структуризации адресного пространства
- Путем отбрасывания k+n младших разрядов в виртуальном адресе определяется номер раздела, к которому принадлежит данный виртуальный адрес.
- По этому номеру из таблицы разделов извлекается дескриптор соответствующей таблицы страниц. Проверяется, находится ли данная таблица страниц в памяти. Если нет, происходит страничное прерывание и система загружает нужную страницу с диска.
- Далее из этой таблицы страниц извлекается дескриптор виртуальной страницы, номер которой содержится в средних п разрядах преобразуемого виртуального адреса. Снова выполняется проверка наличия данной страницы в памяти и при необходимости ее загрузка.
- Из дескриптора определяется номер (базовый адрес) физической страницы, в которую загружена данная виртуальная страница. К номеру физической страницы пристыковывается смещение, взятое из к младших разрядов виртуального адреса. В результате получается искомый физический адрес.
2) Инвертированные таблицы страниц
Достоинства:
· гораздо меньше по объёму.
Недостатки:
· не совсем ясно, как в ней искать виртуальный адрес.
Этот подход применяется на машинах PowerPC, некоторых рабочих станциях Hewlett-Packard, IBM RT, IBM AS/400 и ряде других.
В этой таблице содержится по одной записи на каждый страничный кадр физической памяти. Существенно, что достаточно одной таблицы для всех процессов. Таким образом, для хранения функции отображения требуется фиксированная часть основной памяти, независимо от разрядности архитектуры, размера и количества процессов. Например, для компьютера Pentium c 256 Мбайт оперативной памяти нужна таблица размером 64 Кбайт строк.
Несмотря на экономию оперативной памяти, применение инвертированной таблицы имеет существенный минус – записи в ней (как и в ассоциативной памяти) не отсортированы по возрастанию номеров виртуальных страниц, что усложняет трансляцию адреса. Один из способов решения данной проблемы – использование хеш-таблицы виртуальных адресов. При этом часть виртуального адреса, представляющая собой номер страницы, отображается в хеш-таблицу с использованием функции хеширования. Каждой странице физической памяти соответствует одна запись в хеш-таблице и инвертированной таблице страниц. Виртуальные адреса, имеющие одно значение хеш-функции, сцепляются друг с другом. Обычно длина цепочки не превышает двух записей. в начало
39.
Алгоритмы
замещения страниц.
1)
Оптимальный
(нереализуемый)
Каждая страница должна быть помечена количеством команд, которые выполняются до первого обращения к странице. Суть: на выгрузку выбирается страница, имеющая пометку наибольшим значением.
2)
Исключение
недавно использованных страниц
Бит R – бит обращения, бит M – бит обращения.
Суть:
1 при запуске процесса R=0, M=0 для всех страниц.
2 При каждом прерывании по таймеру бит R сбрасывается
3 При возникновении ошибки отсутствия страницы ОС просматривает все дескрипторы страниц и делит их на четыре категории:
Класс 0: ни обращений, ни модификации
Класс 1: нет обращений, есть модификация
Класс 2: есть обращения, нет модификации
Класс 3: есть обращения, есть модификация
Алгоритм удаляет произвольную страницу низшего класса.
1)
Алгоритм «первый
пришёл, первый ушёл» (FIFO)
Страницы хранятся в связанном списке, по порядку загрузки. Выгружается та страница, которая стоит в начале списка (загружена первой)
Достоинства:
· простой алгоритм.
2)
«Второй шанс»
Как в FIFO, но если у первой страницы бит R=0, то она удаляется, а если бит R=1, то он сбрасывается, а страница отправляется в конец списка. Если ко всем страницам есть обращение – вырождается в FIFO.
3)
«Часы»
Циклический список. Если R=0, страница выгружается, на её место загружается новая. Если R=1, то R сбрасывается, стрелка идёт дальше.
![]()
4)
LRU – Least recently
used
1 Связанный список всех страниц. Первая страница – только что использованная. Использовали – переместили в начало.
Недостатки:
· очень долгий даже на аппаратном уровне.
2 Страницам ввести счётчик. Удаляются страницы с наименьшим счётчиком
Использовали - +1.
3
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
0 |
|
1 |
1 |
0 |
1 |
1 |
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
0 |
Если использовали страницу, элементы строки k увеличиваются на 1, элементы столбца k обнуляются. Удаляются страницы с наименьшим значением строки.
5)
Алгоритм
нечастого использования
Программный счётчик, при каждом прерывании от таймера ОС сканирует все находящиеся в памяти страницы, если R=1, счётчик увеличивается на 1. Таким образом, кандидатом на освобождение оказывается страница с наименьшим значением счетчика, как страница, к которой реже всего обращались. Главный недостаток алгоритма NFU состоит в том, что он ничего не забывает. Например, страница, к которой очень часто обращались в течение некоторого времени, а потом обращаться перестали, все равно не будет удалена из памяти, потому что ее счетчик содержит большую величину. Например, в многопроходных компиляторах страницы, которые активно использовались во время первого прохода, могут надолго сохранить большие значения счетчика, мешая загрузке полезных в дальнейшем страниц.
К счастью, возможна небольшая модификация алгоритма, которая позволяет ему "забывать". Достаточно, чтобы при каждом прерывании по времени содержимое счетчика сдвигалось вправо на 1 бит, а уже затем производилось бы его увеличение для страниц с установленным флагом обращения.
Другим, уже более устойчивым недостатком алгоритма является длительность процесса сканирования таблиц страниц.
6)
«Рабочий набор»
Рабочий набор - множество страниц (к), которое процесс использовал до момента времени (t). Т.е. можно записать функцию w(k,t).
Рисунок 15. Зависимость рабочего набора w(k,t) от количества
запрошенных страниц
Т.е. рабочий набор выходит в насыщение, значение w(k,t) в режиме насыщения может служить для рабочего набора, который необходимо загружать до запуска процесса.
Алгоритм заключается в том, чтобы определить рабочий набор, найти и выгрузить страницу, которая не входит в рабочий набор. Этот алгоритм можно реализовать, записывая, при каждом обращении к памяти, номер страницы в специальный сдвигающийся регистр, затем удалялись бы дублирующие страницы. Но это дорого. В принципе можно использовать множество страниц, к которым обращался процесс за последние t секунд.
Текущее виртуальное время (Tv) - время работы процессора, которое реально использовал процесс.
Время последнего использования (Told) - текущее время при R=1, т.е. все страницы проверяются на R=1, и если да то текущее время записывается в это поле.
Теперь можно вычислить возраст страницы (не обновления) Tv-Told, и сравнить с t, если больше, то страница не входит в рабочий набор, и страницу можно выгружать.
Получается три варианта:
· если R=1, то текущее время запоминается в поле время последнего использования
· если R=0 и возраст > t, то страница удаляется
· если R=0 и возраст =< t, то эта страница входит в рабочий набор
7) WSClock
Алгоритм основан на алгоритме "часы", но использует рабочий набор. Используются битов R и M, а также время последнего использования. Это достаточно реальный алгоритм, который используется на практике.
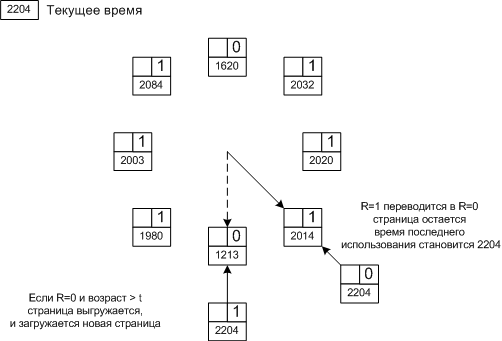
Рисунок 16. Работа алгоритма WSClock в начало
40.
Сегментное
распределение памяти.
Страничная организация виртуального адресного пространства не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это часто бывает очень полезным. При сегментном способе организации памяти виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса, в которой для каждого сегмента указывается:
· - начальный физический адрес сегмента в оперативной памяти;
· - размер сегмента;
· - правила доступа;
· - признаки модификации, присутствия, обращения к данному сегменту.
Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту. Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, а s - смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s. Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса. в начало
41.
Сегментно-страничное
распределение памяти.
Сегментно-страничное распределение представляет собой комбинацию страничного и сегментного механизма управления памятью и направлен на реализацию достоинств обоих методов. Так же как и при сегментной организации памяти, виртуальное адресное пространство процесса разделено на сегменты. Это позволяет определить разные права доступа к разным частям кодов и данных программы. Перемещение данных между памятью и диском осуществляется не сегментами, а страницами. Для этого каждый виртуальный сегмент и физическая память делятся на страницы равного размера, что позволяет более эффективно использовать память, сократив фрагментацию. В большинстве современных реализаций сегментно-страничной организации памяти все виртуальные сегменты образуют одно непрерывное линейное виртуальное адресное пространство. Для каждого процесса ОС создает отдельную таблицу сегментов, в которой содержатся дескрипторы всех сегментов процесса. Описание сегмента включает назначенные ему права доступа и другие характеристики, подобные тем, которые содержатся в дескрипторах сегментов при сегментной организации памяти. В поле базового адреса указывается не начальный физический адрес сегмента, отведенный ему при загрузке в оперативную память, а начальный линейный виртуальный адрес сегмента в пространстве виртуальных адресов. Исходный виртуальный адрес, заданный в виде пары (сегмент : смещение) однозначно преобразуется в линейный виртуальный адрес байта, который затем преобразуется в физический адрес страничным механизмом. в начало
42.
Средства поддержки
сегментации памяти в МП Intel Pentium.
Физическое адресное пространство процессора i386 составляет 4 Гбайта, что определяется 32-разрядной шиной адреса. Физическая память является линейной с адресами от 00000000 до FFFFFFFF в шестнадцатеричном представлении. Виртуальный адрес, используемый в программе, представляет собой пару - номер сегмента и смещение внутри сегмента. Смещение хранится в соответствующем поле команды, а номер сегмента - в одном из шести сегментных регистров процессора (CS, SS, DS, ES, FS или GS), каждый из которых является 16-битным. Средства сегментации образуют верхний уровень средств управления виртуальной памятью процессора i386, а средства страничной организации - нижний уровень. Средства страничной организации могут быть как включены, так и выключены (за счет установки определенного бита в управляющем регистре процессора), и в зависимости от этого изменяется смысл преобразования виртуального адреса, которое выполняют средства сегментации. Сначала рассмотрим случай работы средств сегментации при отключенном механизме управления страницами.
32-битное смещение определяет размер виртуального сегмента в 232=4 Гбайта, а количество сегментов определяется размером поля, отведенного в сегментном регистре под номер сегмента. Структура данных в сегментном регистре называется селектором, так как предназначена для выбора дескриптора определенного сегмента из таблиц дескрипторов сегментов. Дескриптор сегмента описывает все характеристики сегмента, необходимые для проверки правильности доступа к нему и нахождения его в физическом адресном пространстве. Процессор i386 поддерживает две таблицы дескрипторов сегментов - глобальную (Global Descriptor Table, GDT) и локальную (Local Descriptor Table, LDT). Глобальная таблица предназначена для описания сегментов операционной системы и сегментов межзадачного взаимодействия, то есть сегментов, которые в принципе могут использоваться всеми процессами, а локальная таблица - для сегментов отдельных задач. Таблица GDT одна, а таблиц LDT должно быть столько, сколько в системе выполняется задач. При этом активной в каждый момент времени может быть только одна из таблиц LDT.
Селектор состоит из трех полей - 13-битного поля индекса (номера сегмента) в таблицах GDT и LDT, 1-битного поля - указателя типа используемой таблицы дескрипторов и двухбитного поля текущих прав доступа задачи - CPL. Разрядность поля индекса определяет максимальное число глобальных и локальных сегментов задачи - по 8K (213) сегментов каждого типа, всего 16 K. С учетом максимального размера сегмента - 4 Гбайта - каждая задача при чисто сегментной организации виртуальной памяти работает в виртуальном адресном пространстве в 64 Тбайта. в начало
43.
Сегментный режим
распределения памяти в МП Intel Pentium.
При загрузке процесса в оперативную память помещается только часть его сегментов, полная копия виртуального адресного пространства находится в дисковой памяти. Для каждого загружаемого сегмента операционная система подыскивает непрерывный участок свободной памяти достаточного размера. Смежные в виртуальной памяти сегменты одного процесса могут занимать в оперативной памяти несмежные участки. Если во время выполнения процесса происходит обращение по виртуальному адресу, относящемуся к сегменту, который в данный момент отсутствует в памяти, то происходит прерывание. ОС приостанавливает активный процесс, запускает на выполнение следующий процесс из очереди, а параллельно организует загрузку нужного сегмента с диска. При отсутствии в памяти места, необходимого для загрузки сегмента, операционная система выбирает сегмент на выгрузку, при этом она использует критерии, аналогичные рассмотренным выше критериям выбора страниц при страничном способе управления памятью.
На этапе создания процесса во время загрузки его образа в оперативную память система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается:
· базовый физический адрес сегмента в оперативной памяти;
· размер сегмента;
· правила доступа к сегменту;
· признаки модификации, присутствия и обращения к данному сегменту, а также некоторая другая информация.
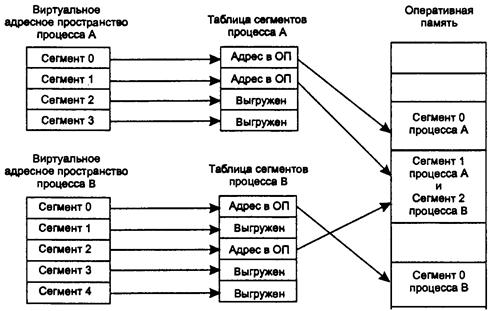
Рисунок 17. Распределение памяти сегментами
Если виртуальные адресные пространства
нескольких процессов включают один и тот же сегмент, то в таблицах сегментов
этих процессов делаются ссылки на один и тот же участок оперативной памяти, в
который данный сегмент загружается в единственном экземпляре.
Виртуальный адрес при сегментной
организации памяти может быть представлен парой (g, s), где g — номер сегмента,
as — смещение в сегменте. Физический адрес получается путем сложения базового
адреса сегмента, который определяется по номеру сегмента g из таблицы сегментов
и смещения s.
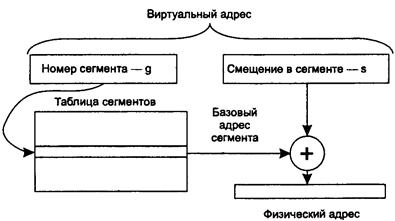
Рисунок 18. Преобразование виртуального адреса при сегментной
организации памяти
В данном случае нельзя
обойтись операцией конкатенации, как это делается при страничной организации
памяти. Действительно, поскольку размер страницы равен степени двойки,
следовательно, в двоичном виде он выражается числом с несколькими нулями в
младших разрядах. Страницы имеют одинаковый размер, а значит, их начальные
адреса кратны размеру страниц и выражаются также числами с нулями в младших разрядах.
Именно поэтому ОС заносит в таблицы страниц не полные адреса, а номера физических
страниц, которые совпадают со старшими разрядами базовых адресов. Сегмент же
может в общем случае располагаться в физической памяти начиная с любого адреса,
следовательно, для определения местоположения в памяти необходимо задавать его
полный начальный физический адрес. Использование операции сложения вместо
конкатенации замедляет процедуру преобразования виртуального адреса в
физический по сравнению со страничной организацией.
Другим недостатком
сегментного распределения является избыточность. При сег-ментной организации
единицей перемещения между памятью и диском является сегмент, имеющий в общем
случае объем больший, чем страница. Однако во многих случаях для работы
программы вовсе не требуется загружать весь сегмент целиком, достаточно было бы
одной или двух страниц. Аналогично при отсутствии свободного места в памяти не
стоит выгружать целый сегмент, когда можно обойтись выгрузкой нескольких
страниц.
Но главный недостаток
сегментного распределения — это фрагментация, которая возникает из-за непредсказуемости
размеров сегментов. В процессе работы системы в памяти образуются небольшие
участки свободной памяти, в которые не может быть загружен ни один сегмент.
Суммарный объем, занимаемый фрагментами, может составить существенную часть общей
памяти системы, приводя к ее неэффективному использованию.
Одним из существенных отличий
сегментной организации памяти от страничной является возможность задания
дифференцированных прав доступа процесса к его сегментам. Например, один
сегмент данных, содержащий исходную информацию для приложения, может иметь
права доступа «только чтение», а сегмент данных, представляющий результаты, —
«чтение и запись». Это свойство дает принципиальное преимущество сегментной
модели памяти над страничной. в начало
44.
Сегментно-страничный
режим распределения памяти в МП Intel Pentium.
Преобразование виртуального адреса в физический происходит в два этапа:
1)
На первом этапе работает механизм сегментации.
Исходный виртуальный адрес, заданный в виде пары (номер сегмента, смещение),
преобразуется в линейный виртуальный адрес. Для этого на основании базового
адреса таблицы сегментов и номера сегмента вычисляется адрес дескриптора
сегмента. Анализируются поля дескриптора и выполняется проверка возможности
выполнения заданной операции. Если доступ к сегменту разрешен, то вычисляется
линейный виртуальный адрес путем сложения базового адреса сегмента,
извлеченного из дескриптора, и смещения, заданного в исходном виртуальном
адресе.
2)
На втором этапе работает страничный механизм.
Полученный линейный виртуальный адрес преобразуется в искомый физический адрес.
В результате пре-образования линейный виртуальный адрес представляется в том
виде, в котором он используется при страничной организации памяти, а именно в
виде пары (номер страницы, смещение в странице). Благодаря тому что размер
страницы выбран равным степени двойки, эта задача решается простым отделением
некоторого количества младших двоичных разрядов. При этом в старших разрядах
содержится номер виртуальной страницы, а в младших — смещение искомого элемента
относительно начала страницы. Так, если размер страницы равен 2к, то смещением
является содержимое младших к разрядов, а остальные,
старшие разряды содержат номер виртуальной страницы, которой принадлежит
искомый адрес. Далее преобразование адреса происходит так же, как при
страничной организации: старшие разряды линейного виртуального адреса,
содержащие номер виртуальной страницы, заменяются номером физической страницы,
взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие
смещение, остаются без изменения.
Именно такой подход реализован компанией Intel в процессорах Pentium.
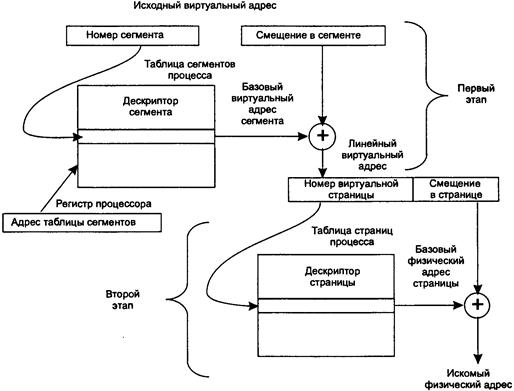
Рисунок 19. Преобразование виртуального адреса в физический при
сегментно-страничной организации памяти в начало
45.
Средства защиты
памяти в МП Intel Pentium.
Защита памяти — это избирательная
способность предохранять выполняемую задачу от записи или чтения памяти,
назначенной другой задаче. Правильно написанные программы не пытаются
обращаться к памяти, назначенной другим. Однако реальные программы часто
содержат ошибки, в результате которых такие попытки иногда предпринимаются.
Средства защиты памяти, реализованные в операционной системе, должны пресекать
несанкционированный доступ процессов к чужим областям памяти.
В Intel-Pentium в аппаратном дескрипторе сегмента
предусмотрено пять двоичных разрядов, которые могут
быть использованы для целей защиты памяти , а в дескрипторе страницы -
только два таких разряда. Однако объединение средств защиты на уровне каталога
страниц и таблиц второго уровня образует достаточно богатые возможности.
Надежность защиты памяти в современных ОС определяется только тем, насколько
активно и аккуратно эти возможности используются. в начало
46.
Кэш-память
(понятие, принцип действия кэш-памяти).
Кэш-память, или просто кэш — это способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который за счет динамического копирования в «быстрое» ЗУ. Наиболее часто используемой информации из «медленного» ЗУ позволяет, с одной стороны, уменьшить среднее время доступа к данным, а с другой стороны, экономить более дорогую быстродействующую память.
Неотъемлемым свойством кэш-памяти
является ее прозрачность для программ и пользователей. Система не требует
никакой внешней информации об интенсивности использования данных; ни
пользователи, ни программы не принимают никакого участия в перемещении данных
из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными
средствами.
Кэш-памятью, или кэшем, часто называют
не только способ организации работы двух типов запоминающих устройств, но и
одно из устройств — «быстрое» ЗУ.
Принцип действия
Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных из основной памяти. Каждая запись об элементе данных включает в себя:
· значение элемента данных;
· адрес, который этот элемент данных имеет в основной памяти;
· дополнительную информацию, которая используется для реализации алгоритма замещения данных в кэше и обычно включает признак модификации и признак действительности данных.
При каждом обращении к основной памяти по физическому адресу просматривается содержимое кэш-памяти с целью определения, не находятся ли там нужные данные. Кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому — по взятому из запроса значению поля адреса в оперативной памяти. Далее возможен один из двух вариантов развития событий:
· если данные обнаруживаются в кэш-памяти, то есть произошло кэш-попадание (cache-hit), они считываются из нее и результат передается источнику запроса;
· если нужные данные отсутствуют в кэш-памяти, то есть произошел кэш-промах (cache-miss), они считываются из основной памяти, передаются источнику запроса и одновременно с этим копируются в кэш-память.
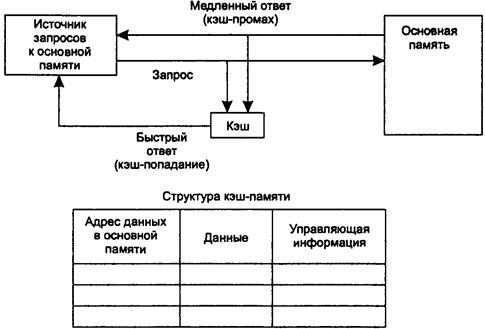
Рисунок 20. Схема функционирования кэш-памяти
Интуитивно понятно, что эффективность кэширования зависит от вероятности попадания в кэш.
Алгоритм поиска и алгоритм
замещения данных в кэше непосредственно зависят от того, каким образом основная
память отображается на кэш-память. Принцип прозрачности требует, чтобы правило
отображения основной памяти на кэш-память не зависело от работы программ и
пользователей. При кэшировании данных из оперативной памяти широко используются
две основные схемы отображения: случайное отображение и детерминированное
отображение. в начало
47.
Случайное
отображение основной памяти на кэш.
При случайном отображении элемент оперативной памяти в общем случае может быть размещен в произвольном месте кэш-памяти. Для того чтобы в дальнейшем можно было найти нужные данные в кэше, они помещаются туда вместе со своим адресом, то есть тем адресом, который данные имеют в оперативной памяти. При каждом запросе к оперативной памяти выполняется поиск в кэше, причем критерием поиска выступает адрес оперативной памяти из запроса. Очевидная схема простого перебора для поиска нужных данных в случае кэша оказывается непригодной из-за недопустимо больших временных затрат.
Для кэшей со случайным отображением используется так называемый ассоциативный поиск, при котором Сравнение выполняется не последовательно с каждой записью кэша, а параллельно со всеми его записями. Признак, По которому выполняется сравнение, называется тегом. В данном случае тегом являете адрес данных в оперативной памяти. Электронная реализация такой схемы приводит к удорожанию памяти, причем стоимость существенно возрастает с увеличением объема запоминающего устройства. Поэтому ассоциативная кэш-память используется в тех случаях, когда для обеспечения высокого процента попадания достаточно небольшого объема памяти.
В кэшах, построенных на основе случайного отображений, вытеснение старых данных происходит только в том случае, когда вся кэш-память заполнена и нет свободного места. Выбор данных на выгрузку осуществляется среди всех записей кэша. Обычно этот выбор основывается на тех же приемах, что и в алгоритмах замещения страниц, например выгрузка данных, к которым дольше всего не было обращений, или данных, к которым было меньше всего обращений.
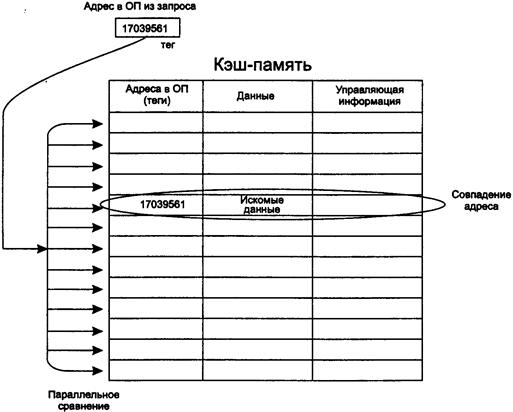
Рисунок 21. Ассоциативный поиск в кэше со случайным отображением
в начало
48.
Детерминированное
отображение основной памяти на кэш.
Детерминированный способ отображения предполагает, что любой элемент основной памяти всегда отображается в одно и то же место кэш-памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных и имеет свой номер. Между номерами строк кэш-памяти и адресами оперативной памяти устанавливается соответствие «один ко многим»: одному номеру строки соответствует несколько (обычно достаточно много) адресов оперативной памяти.
В качестве отображающей функции
может использоваться простое выделение нескольких разрядов из адреса
оперативной памяти, которые интерпретируются как номер строки кэш-памяти (такое
отображение называется прямым).
При поиске данных в кэше
используется быстрый прямой доступ к записи по номеру строки, полученному путем
обработки адреса оперативной памяти из за-проса. Однако поскольку в найденной
строке могут находиться данные из любой ячейки оперативной памяти, младшие
разряды адреса которой совпадают с номером строки, необходимо выполнить
дополнительную проверку. Для этих целей каждая строка кэш-памяти дополняется
тегом, содержащим старшую часть адреса данных в оперативной памяти. При
совпадении тега с соответствующей частью адреса из запроса констатируется кэш-попадание.
Если же произошел кэш-промах, то данные считываются из оперативной памяти и копируются в кэш. Если строка кэш-памяти, в которую должен быть скопирован элемент данных из оперативной памяти, содержит другие данные, то последние вытесняются из кэша. Заметим, что процесс замещения данных в кэш-памяти на основе прямого отображения существенно отличается от процесса замещения данных в кэш-памяти со случайным отображением. Во-первых, вытеснение данных происходит не только в случае отсутствия свободного места в кэше, во-вторых, никакого выбора данных на замещение не существует.
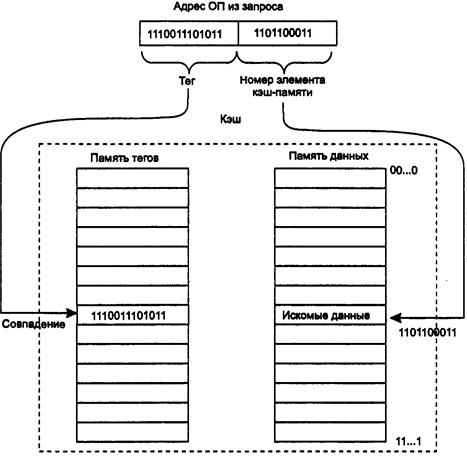
Рисунок 22. Прямое отображение в начало
49.
Комбинированный
способ отображения основной памяти на кэш.
Во многих современных процессорах кэш-память строится на основе сочетания этих двух подходов, что позволяет найти компромисс между сравнительно низкой стоимостью кэша с прямым отображением и интеллектуальностью алгоритмов замещения в кэше со случайным отображением. При смешанном подходе произвольный адрес оперативной памяти отображается не на один адрес кэш-памяти (что характерно для прямого отображения) и не на любой адрес кэш-памяти (как это делается при случайном отображении), а на некоторую группу адресов. Все группы пронумерованы. Поиск в кэше осуществляется вначале по номеру группы, полученному из адреса оперативной памяти из запроса, а затем в пределах группы путем ассоциативного просмотра всех записей в группе на предмет совпадения старших частей адресов оперативной памяти.
При промахе данные копируются по любому свободному адресу из однозначно заданной группы. Если свободных адресов в группе нет, то выполняется вытеснение данных. Поскольку кандидатов на выгрузку несколько — все записи из данной группы — алгоритм замещения может учесть интенсивность обращений к данным и тем самым повысить вероятность попаданий в будущем. Таким образом, в данном способе комбинируется прямое отображение на группу и случайное отображение в пределах группы.
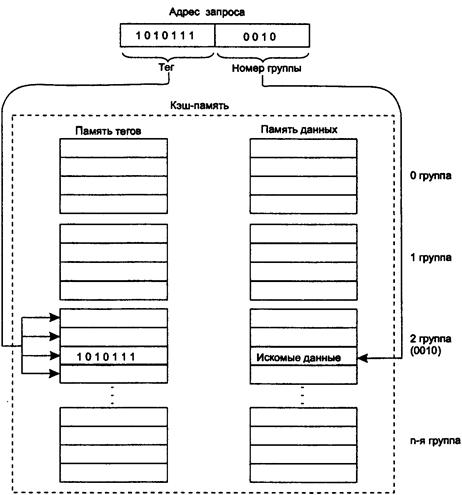
Рисунок 23. Комбинирования прямого и случайного отображения
в начало
50.
Кэширование в МП
Intel Pentium. Буфер ассоциативной трансляции
Кэширование в процессоре Pentium
В процессоре Pentium кэширование
используется в следующих случаях.
·
Кэширование дескрипторов сегментов в скрытых
регистрах. Для каждого сегментного регистра в процессоре имеется так называемый
скрытый регистр дескриптора. В скрытый регистр при загрузке сегментного
регистра помещается информация из дескриптора, на который указывает данный
сегментный регистр. Информация из дескриптора сегмента используется для
преобразования виртуального адреса в физический при чисто сегментной
организации памяти либо для получения линейного виртуального адреса при
страничном механизме. Доступ к скрытому регистру выполняется быстрее, чем поиск
и извлечение информации из таблицы страниц, находящейся в оперативной памяти.
Поэтому если очередное обращение будет относиться к одному из сегментов,
дескриптор которого еще хранится в скрытом регистре (а вероятность этого
велика), то преобразование адресов будет выполнено быстрее. Тем самым скрытые
регистры играют роль кэша таблицы дескрипторов и ускоряют работу процессора.
·
Кэширование пар номеров виртуальных и
физических страниц в буфере ассоциативной трансляции TLB (Translation Lookaside
Buffer) позволяет ускорять преобразование виртуальных адресов в физические при
сегментно-странич-ной организации памяти. TLB представляет собой ассоциативную
память небольшого объема, предназначенную для хранения интенсивно используемых
дескрипторов страниц. В процессоре Pentium имеются отдельные TLB для инструкций
и данных.
·
Кэширование данных и инструкций в кэш-памяти
первого уровня. Эта память, называемая также внутренней кэш-памятью, поскольку
она размещена непосредственно на кристалле микропроцессора, имеет объем 16/32
Кбайт. В процессоре Pentium кэш первого уровня разделен на память для хранения
данных и память для хранения инструкций. Согласование данных выполняется только
методом сквозной записи.
·
Кэширование данных и инструкций в кэш-памяти
второго уровня. Эта память называется также внешней кэш-памятью, поскольку она
устанавливается в виде отдельной микросхемы на системной плате. Кэш-память
второго уровня является общей для данных и инструкций и имеет объем 256/512
Кбайт. Поиск в кэше второго уровня выполняется в случае, когда констатируется
промах в кэше первого уровня. Для согласования данных в кэше второго уровня
может использоваться как сквозная, так и обратная запись.
Буфер ассоциативной трансляции
В буфере
TLB кэшируются дескрипторы страниц из таблицы страниц. Для хранения дескриптора
в кэше отводится одна строка. Каждая строка дополнена тегом, в котором
содержится номер соответствующей виртуальной страницы. Строки объединены по
четыре в группы, называемые наборами. Таблица TLB, используемая для преобразования
адресов инструкций, имеет 32 строки и соответственно 8 наборов. Номер набора
называют индексом (index). Таким образом, путем кэширования может быть получен
физический адрес для доступа к 32 страницам памяти, содержащим инструкции.
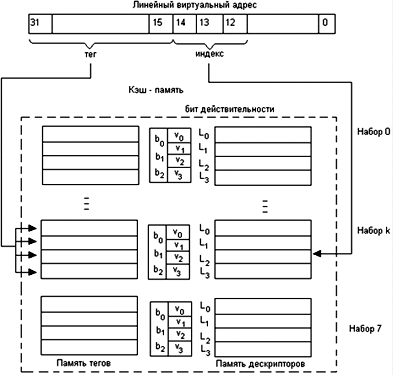
Рисунок 24. Буфер ассоциативной трансляции
![]() После того как механизмом
сегментации получен линейный адрес, он должен быть преобразован в физический
адрес. Для этого прежде всего необходимо найти дескриптор страницы, к которой
принадлежит данный адрес, и извлечь из него номер физической страницы. Обычная
процедура предусматривает обращение к таблице разделов, а затем к таблице
страниц. Однако физический адрес может быть получен гораздо быстрее благодаря
тому, что в буфере TLB хранятся копии дескрипторов наиболее интенсивно
используемых страниц. Поэтому перед тем, как начать сравнительно длительную
процедуру преобразования адресов, делается попытка обнаружить нужный дескриптор
страницы в быстрой ассоциативной памяти TLB. Затем на основании номера
физической страницы, полученного из TLB, вычисляется физический адрес.
После того как механизмом
сегментации получен линейный адрес, он должен быть преобразован в физический
адрес. Для этого прежде всего необходимо найти дескриптор страницы, к которой
принадлежит данный адрес, и извлечь из него номер физической страницы. Обычная
процедура предусматривает обращение к таблице разделов, а затем к таблице
страниц. Однако физический адрес может быть получен гораздо быстрее благодаря
тому, что в буфере TLB хранятся копии дескрипторов наиболее интенсивно
используемых страниц. Поэтому перед тем, как начать сравнительно длительную
процедуру преобразования адресов, делается попытка обнаружить нужный дескриптор
страницы в быстрой ассоциативной памяти TLB. Затем на основании номера
физической страницы, полученного из TLB, вычисляется физический адрес.
При поиске данных в TLB используется линейный виртуальный адрес. Разряды 12-14 используются как индекс набора. Далее проверяются биты действительности v всех строк выбранного набора. В начале работы кэш-памяти биты действительности всех строк сбрасываются в нуль. Бит действительности принимает значение 1, когда в соответствующей строке содержится достоверная информация и сбрасывается в нуль, когда строка объявляется свободной, в результате работы алгоритма замещения. Для всех действительных строк выполняется ассоциативная процедура сравнения тегов со старшими разрядами (15-31 разряд) линейного виртуального адреса. Если произошло кэш-попадание, то номер физической страницы быстро поступает в схему формирования физического адреса.
Если произошел промах и нужного дескриптора в TLB нет, то запускается многоэтапная процедура преобразования адреса, включающая обращения к таблицам разделов и страниц. Когда нужный дескриптор отыскивается в таблице страниц, он копируется в TLB. Номер набора, в который записывается кэшируемый дескриптор, определяется тремя младшими разрядами номера виртуальной страницы (разряды 12-14 линейного виртуального адреса).
Однако поскольку в наборе имеется четыре строки, необходимо определить, в какую именно надо поместить кэшируемые данные. Дескриптор записывается либо в первую попавшуюся свободную строку, либо, если все строки заняты, в строку, к которой дольше всего не обращались. Признаком занятости строки служит бит действительности v, имеющийся у каждой строки. Если v=0, значит, строка свободна для записи в нее нового содержимого. Для определения строки, которая не использовалась дольше всех других в данном наборе, применяется упрощенный вариант алгоритма PseudoLRU (Pseudo Least Recently Used). Этот алгоритм основан на анализе трех бит: b0,b1, bЗ, называемых битами обращения. Биты обращения приписываются набору и устанавливаются в соответствии с алгоритмом, приведенном на рис. 6.18. Здесь L0, LI, L2, L3 обозначают последовательные строки набора.
На замену выбирается одна из следующих строк:
·
L0,
если b0=0 и b1=0;
·
L1,
если b0=0 и b1=1;
·
L2,
если b0=1 и b2=0;
· L3, если b0=1 и b2=1.
Рисунок 25. Алгоритм установки битов обращения
Можно легко показать, что данная процедура не всегда приводит к выбору действительно дольше всех не вызывавшейся строки. Пусть, например, обращения к строкам выполнялись в следующей хронологической последовательности: L0, L2, L3, L1, то есть ближайшее по времени обращение было к строке L1, дольше же всего не было обращений к строке LO. Биты обращения в данном случае примут следующие значения. Поскольку последнее по времени обращение было к строке из пары (LO, L1), значит, Ь0=1. А в паре (L2, L3) последнее обращение было к L3, следовательно, Ь2=0. Отсюда, по правилу, приведенному выше, на замену выбирается строка L2, вместо строки L0, к которой на самом деле дольше всего не было обращений.
Однако в большинстве случаев этот алгоритм дает результат, совпадающий с оптимальным. Например, для последовательности L0, L3, LI, L2 биты обращения имеют значения b0=0, b1=0, отсюда точное решение — L0. Даже в случае ошибки (вероятность которой составляет 33 %) решения, найденные по алгоритму PseudoLRU, близки к оптимальным. Так, в первом примере вместо строки L0, являющейся правильным решением, алгоритм дал ближайшую к ней по времени обращения строку L2.
Несмотря на то что алгоритм PseudoLRU дает в общем случае приближенные решения, он широко применяется при кэшировании, так как является быстрым и экономичным, что чрезвычайно важно для кэш-памяти.
Таким образом, в буфере TLB процессора Pentium используется комбинированный способ отображения кэшируемых данных на кэш-память: прямое отображение дескрипторов на наборы и случайное отображение на строки в пределах набора.
Наличие TLB позволяет в подавляющем числе случаев заменить сравнительно долгую процедуру преобразования адресов, связанную с несколькими обращениями к оперативной памяти, быстрым поиском в ассоциативной памяти. в начало
51.
Кэширование в МП
Intel Pentium. Кэш первого уровня
Кэширование в процессоре Pentium
В процессоре Pentium кэширование
используется в следующих случаях.
·
Кэширование дескрипторов сегментов в скрытых регистрах.
Для каждого сегментного регистра в процессоре имеется так называемый скрытый
регистр дескриптора. В скрытый регистр при загрузке сегментного регистра
помещается информация из дескриптора, на который указывает данный сегментный
регистр. Информация из дескриптора сегмента используется для преобразования
виртуального адреса в физический при чисто сегментной организации памяти либо
для получения линейного виртуального адреса при страничном механизме. Доступ к
скрытому регистру выполняется быстрее, чем поиск и извлечение информации из
таблицы страниц, находящейся в оперативной памяти. Поэтому если очередное
обращение будет относиться к одному из сегментов, дескриптор которого еще
хранится в скрытом регистре (а вероятность этого велика), то преобразование
адресов будет выполнено быстрее. Тем самым скрытые регистры играют роль кэша
таблицы дескрипторов и ускоряют работу процессора.
·
Кэширование пар номеров виртуальных и
физических страниц в буфере ассоциативной трансляции TLB (Translation Lookaside
Buffer) позволяет ускорять преобразование виртуальных адресов в физические при
сегментно-странич-ной организации памяти. TLB представляет собой ассоциативную
память небольшого объема, предназначенную для хранения интенсивно используемых
дескрипторов страниц. В процессоре Pentium имеются отдельные TLB для инструкций
и данных.
·
Кэширование данных и инструкций в кэш-памяти
первого уровня. Эта память, называемая также внутренней кэш-памятью, поскольку
она размещена непосредственно на кристалле микропроцессора, имеет объем 16/32
Кбайт. В процессоре Pentium кэш первого уровня разделен на память для хранения
данных и память для хранения инструкций. Согласование данных выполняется только
методом сквозной записи.
·
Кэширование данных и инструкций в кэш-памяти
второго уровня. Эта память называется также внешней кэш-памятью, поскольку она
устанавливается в виде отдельной микросхемы на системной плате. Кэш-память
второго уровня является общей для данных и инструкций и имеет объем 256/512
Кбайт. Поиск в кэше второго уровня выполняется в случае, когда констатируется
промах в кэше первого уровня. Для согласования данных в кэше второго уровня
может использоваться как сквозная, так и обратная запись.
Кэш первого уровня
Кэш первого уровня используется на этапе обработки запроса к основной памяти по физическому адресу.
Работа кэш-памяти первого уровня имеет много общего с работой буфера TLB. В TLB единицей хранения является дескриптор, а в кэше первого уровня — байт данных. Обновление данных в кэше происходит блоками по 16 байт. Таким образом, младшие 4 бита физического адреса байта могут интерпретироваться как смещение в блоке, а старшие разряды — как номер блока.
Для хранения блоков данных в кэше отводятся строки, также имеющие объем 16 байт. Строки объединены в наборы по четыре. При объеме кэша 16 Кбайт в него входят 256 (28) наборов.
При копировании данных в кэш номера блоков основной памяти прямо отображаются на номера наборов. Для этого в адресе основной памяти, относящегося к одному из байтов, входящих в блик, значение 8 битов, находящихся перед битами смещения, интерпретируется как номер набора в кэш-памяти. Остальные старшие биты адреса в дальнейшем используются в качестве тега.
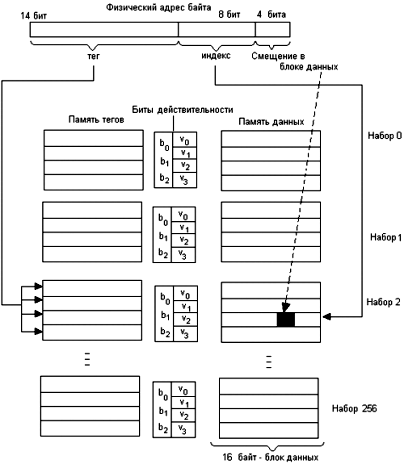
Рисунок 26. Кэш первого уровня процессора Pentium
Так же как в TLB, выбор строки в наборе осуществляется на основе анализа битов действительности и битов обращения по алгоритму PseudoLRU. Блок данных заносится в строку кэш-памяти вместе со своим тегом — старшими разрядами адреса основной памяти. Бит действительности строки устанавливается в 1.
При возникновении запроса на чтение из основной памяти вначале делается попытка найти данные в кэше (либо поиск в кэше совмещается с выполнением запроса к основной памяти). По индексу, извлеченному из адреса запроса, определяется набор, в котором могут находиться искомые данные. Затем для строк данного набора, содержимое которых действительно (установлены биты действительности), выполняется ассоциативный поиск: старшие разряды адреса из запроса сравниваются с тегами всех строк набора. Если для какой-нибудь строки фиксируется совпадение, это означает, что произошло кэш-попадание, и из соответствующей строки извлекается байт, смещение которого относительно начала строки определяется четырьмя младшими разрядами из адреса запроса.
Для согласования данных в кэше первого уровня используется метод сквозной записи, то есть при возникновении запроса на запись обновляется не только содержимое соответствующей ячейки основной памяти, но и его копия в кэш-памяти. Заметим также, что запрос на запись при промахе не вызывает обновления кэша. в начало
52.
Задачи ОС по управлению
файлами и устройствами
Подсистема ввода-вывода
(Input-Output Subsystem) мультипрограммной ОС при обмене данными с внешними
устройствами компьютера должна решать ряд общих задач, из которых наиболее
важными являются
следующие:
·
организация параллельной работы устройств
ввода-вывода и процессора;
·
согласование скоростей обмена и кэширование
данных;
·
разделение устройств и данных между
процессами;
·
обеспечение удобного логического интерфейса
между устройствами и остальной частью системы;
·
поддержка широкого спектра драйверов с
возможностью простого включения в систему нового драйвера;
·
динамическая загрузка и выгрузка драйверов;
·
поддержка нескольких файловых систем;
·
поддержка синхронных и асинхронных операций
ввода-вывода.
Организация параллельной работы устройств
ввода-вывода и процессора
Каждое устройство ввода-вывода вычислительной системы снабжено специализированным блоком управления, называемым контроллером. Контроллер взаимодействует с драйвером. Контроллер периодически принимает от драйвера выводимую на устройство информацию, а также команды управления, которые говорят о том, что с этой информацией нужно сделать.
Процессы, происходящие в контроллерах, протекают в периоды между выдачами команд независимо от ОС. От подсистемы ввода-вывода требуется спланировать в реальном масштабе времени запуск и приостановку большого количества разнообразных драйверов, обеспечив приемлемое время реакции каждого драйвера на независимые события контроллера. С другой стороны, необходимо минимизировать загрузку процессора задачами ввода-вывода, оставив как можно больше процессорного времени на выполнение пользовательских потоков.
Данная задача является классической задачей планирования систем реального времени и обычно решается на основе многоуровневой приоритетной схемы обслуживания по прерываниям. Для обеспечения приемлемого уровня реакции все драйверы (или части драйверов) распределяются по нескольким приоритетным уровням в соответствии с требованиями ко времени реакции и временем использования процессора. Для реализации приоритетной схемы обычно задействуется общий диспетчер прерываний ОС.
Согласование скоростей обмена и кэширование
данных
При обмене данными всегда возникает задача согласования скорости. Например, если один пользовательский процесс вырабатывает некоторые данные и передает их другому пользовательскому процессу через оперативную память, то в общем случае скорости генерации данных и их чтения не совпадают. Согласование скорости обычно достигается за счет буферизации данных в оперативной памяти и синхронизации доступа процессов к буферу.
Буферизация только на основе оперативной памяти в подсистеме ввода-вывода оказывается недостаточной — разница между скоростью обмена с оперативной памятью, куда процессы помещают данные для обработки, и скоростью работы внешнего устройства часто становится слишком значительной, чтобы в качестве временного буфера можно было бы использовать оперативную память. Часто в качестве буфера используется дисковый файл, называемый также спул-файлом.
Другим решением этой проблемы является использование большой буферной памяти в контроллерах внешних устройств. Такой подход особенно полезен в тех случаях, когда помещение данных на диск слишком замедляет обмен (или когда данные выводятся на сам диск). Например, в контроллерах графических дисплеев применяется буферная память, соизмеримая по объему с оперативной, и это существенно ускоряет вывод графики на экран.
Буферизация данных позволяет не только согласовать скорости работы процессора и внешнего устройства, но и решить другую задачу — сократить количество реальных операций ввода-вывода за счет кэширования данных.
Разделение устройств и данных между
процессами
Одно и то же устройство в разные периоды времени может использоваться как в разделяемом, так и в монопольном режимах. Тем не менее существуют устройства, для которых обычно характерен один из этих режимов, например последовательные порты и алфавитно-цифровые терминалы чаще используются в монопольном режиме, а диски — в режиме совместного доступа. Операционная система должна предоставлять эти устройства в обоих режимах, осуществляя отслеживание процедур захвата и освобождения монопольно используемых устройств, а в случае совместного использования оптимизируя последовательность операций ввода-вывода для различных процессов в целях повышения общей производительности, если это возможно. Например, при обмене данными нескольких процессов с диском можно так упорядочить последовательность операций, что непроизводительные затраты времени на перемещение головок существенно уменьшаются.
При разделении устройства между процессами может возникнуть необходимость в разграничении порции данных двух процессов друг от друга. Обычно такая потребность возникает при совместном использовании так называемых последовательных устройств, данные в которых в отличие от устройств прямого доступа не адресуются. Типичным представителем такого рода устройства является принтер, который не выделяется в монопольное владение процессам, и в то же время каждый документ должен быть напечатан в виде последовательного набора страниц. Для подобных устройств организуется очередь заданий на вывод, при этом каждое задание представляет собой порцию данных, которую нельзя разрывать, например документ для печати. Для хранения очереди заданий используется спул-файл, который одновременно согласует скорости работы принтера и оперативной памяти и позволяет организовать разбиение данных на логические порции. Так как спул-файл находится на разделяемом устройстве прямого доступа, то процессы могут одновременно выполнять вывод на принтер, помещая данные в свой раздел спул-файла.
Обеспечение удобного логического интерфейса
между устройствами и остальной частью системы
Разнообразие устройств ввода-вывода делают особенно актуальной функцию ОС по созданию экранирующего логического интерфейса между периферийными устройствами и приложениями. Практически все современные операционные системы поддерживают в качестве основы такого интерфейса файловую модель периферийных устройств, когда любое устройство выглядит для прикладного программиста последовательным набором байт, с которым можно работать с помощью унифицированных системных вызовов (например, read и write), задавая имя файла-устройства и смещение от начала последовательности байт. Для поддержания такого интерфейса подсистема ввода-вывода должна проделать немалую работу, учитывая разницу в организации операций обмена данными, например, с жестким диском и графическим терминалом.
Привлекательность модели файла-устройства состоит в ее простоте и унифицированности для устройств любого типа, однако во многих случаях для программирования операций ввода-вывода некоторого устройства она является слишком бедной. Поэтому данная модель часто используется только в качестве базиса, над которым подсистема ввода-вывода строит более содержательную модель устройств конкретного типа. Подсистема ввода-вывода предоставляет, как правило, специфический интерфейс для вывода графической информации на дисплей или принтер, для программирования операций сетевого обмена и т. п. При этом разработчик специфического интерфейса всегда может опираться на имеющийся базовый интерфейс.
Поддержка широкого спектра драйверов и
простота включения нового драйвера в систему
Достоинством подсистемы ввода-вывода любой универсальной ОС является наличие разнообразного набора драйверов для наиболее популярных периферийных устройств.
Чтобы операционная система не испытывала недостатка в драйверах, необходимо наличие четкого, удобного и открытого интерфейса между драйверами и другими компонентами ОС. Такой интерфейс нужен для того, чтобы драйверы писали не только непосредственные разработчики данной операционной системы, но и большая армия программистов по всему миру, в первую очередь — тех предприятий, которые выпускают внешние устройства для компьютеров.
Драйвер взаимодействует, с одной стороны, с модулями ядра ОС, а с другой стороны — с контроллерами внешних устройств. Поэтому существуют два типа интерфейсов: интерфейс «драйвер-ядро» (Driver Kernel Interface, DKI) и интерфейс «драйвер-устройство» {Driver Device Interface, DDF). Интерфейс «драйвер-ядро» должен быть стандартизован в любом случае, а интерфейс «драйвер-устройство» имеет смысл стандартизировать тогда, когда подсистема ввода-вывода не разрешает драйверу непосредственно взаимодействовать с аппаратурой контроллера, а выполняет эти операции самостоятельно. Экранирование драйвера от аппаратуры является весьма полезной функцией, так как драйвер в этом случае становится независимым от аппаратной платформы.
Для поддержки процесса разработки драйверов операционной системы обычно выпускается так называемый пакет DDK (Driver Development Kit), представляющий собой набор соответствующих инструментальных средств — библиотек, компиляторов и отладчиков.
Динамическая загрузка и выгрузка драйверов
Кроме проблемы разработки новых драйверов существует также проблема включения драйвера в состав модулей работающей ОС, то есть динамической загрузки-выгрузки драйвера. Так как набор потенциально поддерживаемых данной ОС периферийных устройств всегда существенно шире набора устройств, которыми ОС должна управлять при установке на конкретной машине, то ценным свойством ОС является возможность динамически загружать в оперативную память требуемый драйвер (без останова ОС) и выгружать его после того, как потребность в поддержке устройства миновала, что может существенно сэкономить системную область памяти.
Альтернативой динамической загрузке драйверов является повторная компиляция кода ядра с требуемым набором драйверов, что создает между всеми компонентами ядра статические связи вместо динамических. Например, таким образом решалась данная проблема в ранних версиях операционной системы UNIX. При статических связях между ядром и драйверами структура ОС упрощается, но этот подход требует наличия исходных кодов модулей операционной системы.
Поддержка нескольких файловых систем
Важно чтобы архитектура подсистемы ввода-вывода позволяла достаточно просто включать в ее состав новые типы файловых систем, без необходимости переписывания кода.
Поддержка синхронных и асинхронных операций
ввода-вывода
Операция ввода-вывода может выполняться в синхронном или асинхронном режимах. Смысл этих режимов тот же, что и для рассмотренных выше системных вызовов, — синхронный режим означает, что программный модуль приостанавливает свою работу до тех пор, пока операция ввода-вывода не будет завершена, а при асинхронном режиме программный модуль продолжает выполняться в мультипрограммном режиме одновременно с операцией ввода-вывода. Отличие же заключается в том, что операция ввода-вывода может быть инициирована не только пользовательским процессом — в этом случае операция выполняется в рамках системного вызова, но и кодом ядра, например кодом подсистемы виртуальной памяти для считывания отсутствующей в памяти страницы. в начало
53.
Многослойная
модель подсистемы ввода-вывода
Общая схема
Многослойное построение программного обеспечения, характерное для операционных систем вообще, оказывается особенно естественным и полезным при построении подсистемы ввода-вывода.
Программное обеспечение ввода-вывода делится не только на горизонтальные слои, но и на вертикальные. Это объясняется тем, что трудно обеспечить единообразие в разбиении функций управления на слои. Поэтому общий принцип многослойности остается справедливым, однако для устройств определенного типа он реализуется по-разному, со своим количеством слоев и их функциями.
В каждой вертикальной подсистеме существует несколько слоев модулей. Нижний слой образуют аппаратные драйверы устройств. Функции вышележащих слоев в значительной степени зависят от типа вертикальной подсистемы.
Менеджер ввода-вывода
В подсистеме ввода-вывода наряду с модулями, отражающими специфику внешних устройств и образующими вертикальные подсистемы, существуют модули универсального назначения. Эти модули организуют согласованную работу всех остальных компонентов подсистемы ввода-вывода и взаимодействие с пользовательскими процессами и другими подсистемами ОС. Так же как и функции управления устройствами, эти организующие функции распределены по всем уровням, образуя оболочку. Эта оболочка иногда называется менеджером ввода-вывода. Задачи такого менеджера довольно разнообразны.
Верхний слой менеджера составляют системные вызовы ввода-вывода, которые принимают от пользовательских процессов запросы на ввод-вывод и переадресуют их отвечающим за определенный класс устройств модулям и драйверам, а также возвращают процессам результаты операций ввода-вывода. Таким образом этот слой поддерживает пользовательский интерфейс ввода-вывода, создавая для прикладных программистов максимум удобств по манипулированию внешними устройствами и расположенными на них данными.
Нижний слой менеджера реализует непосредственное взаимодействие с контроллерами внешних устройств, экранируя драйверы от особенностей аппаратной платформы компьютера. Этот слой принимает от драйверов запросы на обмен данными с регистрами контроллеров в некоторой обобщенной форме с использованием независимых от шины ввода-вывода адресации и формата, а затем преобразует эти запросы в зависящий от аппаратной платформы формат. Диспетчер прерываний, рассмотренный выше, может входить в состав менеджера ввода-вывода или же представлять собой отдельный модуль ядра.
Важной функцией менеджера ввода-вывода является создание некоторой среды для остальных компонентов подсистемы, которая бы облегчала их взаимодействие друг с другом. Эта задача может быть решена за счет создания некоторого стандартного внутреннего интерфейса взаимодействия модулей ввода-вывода между собой, который бы дополнял внешние интерфейсы подсистемы с прикладными процессами, другими модулями ядра и аппаратурой. Наличие такого интерфейса существенно облегчает включение новых драйверов и файловых систем в состав ОС. Кроме того, разработчики драйверов и других программных компонентов освобождаются от написания общих процедур, таких как буферизация данных и синхронизация нескольких модулей между собой при обмене данными. Все эти функции берет на себя менеджер ввода-вывода.
Еще одной функцией менеджера ввода-вывода является организация взаимодействия модулей ввода-вывода с модулями других подсистем ОС, таких как подсистема управления процессами, виртуальной памятью и другими.
Многоуровневые драйверы
Первоначально термин «драйвер»
применялся в достаточно узком смысле: под драйвером понимался программный
модуль, который:
·
входит в состав ядра операционной системы,
работая в привилегированном режиме;
·
непосредственно управляет внешним устройством,
взаимодействуя с его контроллером с помощью команд ввода-вывода компьютера;
·
обрабатывает прерывания от контроллера
устройства;
·
предоставляет прикладному программисту удобный
логический интерфейс работы с устройством, экранируя от него низкоуровневые
детали управления устройством и организации его данных;
· взаимодействует с другими модулями ядра ОС с помощью строго оговоренного интерфейса, описывающего формат передаваемых данных, структуру буферов, способы включения драйвера в состав ОС, способы вызова драйвера, набор общих процедур подсистемы ввода-вывода, которыми драйвер может пользоваться, и т. п.
Согласно этому определению драйвер вместе с контроллером устройства и прикладной программой воплощали идею многослойного подхода к организации программного обеспечения. Контроллер представлял нижний слой управления устройством, выполняющий операции в терминах блоков и агрегатов устройства. Драйвер выполнял более сложные операции, преобразуя, например, данные, адресуемые в терминах номеров цилиндров, головок и секторов диска, в линейную последовательность блоков или устанавливая логическое соединение между двумя модемами через телефонную сеть.
Появление высокоуровневых драйверов можно считать дальнейшим развитием идеи многослойной организации подсистемы ввода-вывода. Вместо того чтобы концентрировать все функции по управлению устройством в одном программном модуле, во многих случаях гораздо эффективней распределить их между несколькими модулями в соседних слоях иерархии. Традиционные драйверы стали называть аппаратными драйверами, низкоуровневыми драйверами, или драйверами устройств.
При таком подходе повышается гибкость и расширяемость функций по управлению устройством.
Количество уровней драйверов в подсистеме ввода-вывода обычно не ограничивается каким-либо пределом, но на практике чаще всего используют от двух до пяти уровней драйверов.
Единственным отличием является
то, что высокоуровневые драйверы, как правило, не вызываются по прерываниям,
так как взаимодействуют с управляемым устройством через посредничество
аппаратных драйверов. Менеджер ввода-вывода управляет драйверами однотипно,
независимо от того, к какому уровню он относится. При наличии большого
количества драйверов разного уровня усложняются связи между ними, что, в свою
очередь, усложняет их взаимодействие, и именно эта ситуация привела к
стандартизации внутреннего интерфейса в подсистеме ввода-вывода и выделения
специальной оболочки в виде менеджера ввода-вывода, выполняющего служебные
функции по организации работы драйверов.
Специальные файлы
Специальные файлы, называемые иногда виртуальными, не связаны со статичными наборами данных, хранящихся на дисках, а являются удобным унифицированным представлением устройств ввода-вывода.
Понятие специального файла появилось в операционной системе UNIX. Специальный файл всегда связан с некоторым устройством ввода-вывода и представляет его для остальной части операционной системы и прикладных процессов в виде неструктурированного набора байт. Со специальным файлом можно работать так же, как и с обычным, то есть открывать, считывать из него определенное количество байт или же записывать в него определенное количество байт, а после завершения операции закрывать. Для этого используются те же системные вызовы, что и для работы с обычными файлами. в начало
54.
Физическая
организация жесткого диска.
Диски, разделы, секторы,
кластеры
Основным типом устройства, которое используется в современных вычислительных системах для хранения файлов, являются дисковые накопители. Эти устройства предназначены для считывания и записи данных на жесткие и гибкие магнитные диски. Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом. Таким образом, диск в общем случае состоит из пакета пластин.
На каждой стороне каждой пластины размечены тонкие концентрические кольца — дорожки (traks), на которых хранятся данные. Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, элемент, называемый головкой, считывает двоичные данные с магнитной дорожки или записывает их на магнитную дорожку.
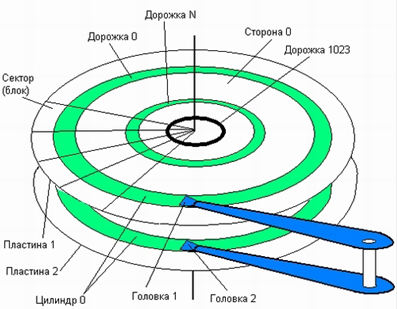
Рисунок 27. Схема физического устройства жесткого диска
Совокупность дорожек одного радиуса на всех поверхностях всех пластин пакета называется цилиндром {cylinder). Каждая дорожка разбивается на фрагменты, называемые секторами (sectors), или блоками (blocks), так что все дорожки имеют равное число секторов, в которые можно максимально записать одно и то же число байт1. Сектор имеет фиксированный для конкретной системы размер, выражающийся степенью двойки. Чаще всего размер сектора составляет 512 байт. Учитывая, что дорожки разного радиуса имеют одинаковое число секторов, плотность записи становится тем выше, чем ближе дорожка к центру.
Сектор — наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Для того чтобы контроллер мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности и номер сектора. Так как прикладной программе в общем случае нужен не сектор, а некоторое количество байт, не обязательно кратное размеру сектора, то типичный запрос включает чтение нескольких секторов, содержащих требуемую информацию, и одного или двух секторов, содержащих наряду с требуемыми избыточные данные.
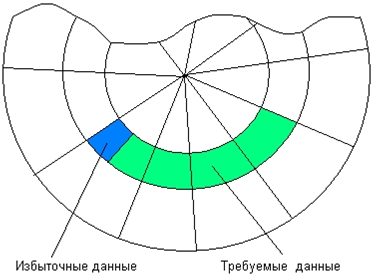
Рисунок 28. Чтение данных из секторов
Операционная система при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером (cluster). При создании файла место на диске ему выделяется кластерами. Например, если файл имеет размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта, то файлу будет выделено на диске 3 кластера.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого, или логического, форматирования.
Диск может быть разбит на разделы. Раздел — это непрерывная часть физического диска, которую операционная система представляет пользователю как логическое устройство. Логическое устройство функционирует так, как если бы это был отдельный физический диск.
Примерами организации совместной работы нескольких дисковых разделов являются так называемые RAID-массивы.
На разных логических устройствах одного и того же физического диска могут располагаться файловые системы разного типа. в начало
55.
Файловая система.
Определение, состав, типы файлов. Логическая организация файловой системы.
Цели и задачи файловой системы
Файловая система (ФС) — это часть операционной системы, включающая:
· совокупность всех файлов на диске;
· наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске;
· комплекс системных программных средств, реализующих различные операции над файлами, такие как создание, уничтожение, чтение, запись, именование и поиск файлов.
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл.
Таким образом, файловая система играет роль промежуточного слоя, экранирующего все сложности физической организации долговременного хранилища данных, и создающего для программ более простую логическую модель этого хранилища, а также предоставляя им набор удобных в использовании команд для манипулирования файлами.
Самый простой тип — это ФС в однопользовательских и однопрограммных ОС. Основные функции в такой ФС нацелены на решение следующих задач:
· именование файлов;
· программный интерфейс для приложений;
· отображения логической модели файловой системы на физическую организацию хранилища данных;
· устойчивость файловой системы к сбоям питания, ошибкам аппаратных и программных средств.
Задачи ФС усложняются в операционных однопользовательских мультипрограммных ОС, которые, хотя и предназначены для работы одного пользователя, но дают ему возможность запускать одновременно несколько процессов. К перечисленным выше задачам добавляется новая задача совместного доступа к файлу из нескольких процессов. Файл в этом случае является разделяемым ресурсом, а значит, файловая система должна решать весь комплекс проблем, связанных с такими ресурсами. В частности, в ФС должны быть предусмотрены средства блокировки файла и его частей, предотвращения гонок, исключение тупиков, согласование копий и т. п.
В многопользовательских системах появляется еще одна задача: защита файлов одного пользователя от несанкционированного доступа другого пользователя.
Еще более сложными становятся функции ФС, которая работает в составе сетевой ОС. Эта тема рассматривается в последней главе книги, посвященной управлению сетевыми ресурсами.
Типы файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых, как правило, входят обычные файлы, файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и другие.
Обычные файлы, или просто файлы, содержат информацию произвольного характера, которую заносит в них пользователь или которая образуется в результате работы системных и пользовательских программ. Двоичные файлы не используют коды символов, они часто имеют сложную внутреннюю структуру, например исполняемый код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов — их собственные исполняемые файлы.
Каталоги — это особый тип файлов, которые содержат системную справочную информацию о наборе файлов, сгруппированных пользователями по какому-либо неформальному признаку.
Специальные файлы — это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к файлам и внешним устройствам. Специальные файлы позволяют пользователю выполнять операции ввода-вывода посредством обычных команд записи в файл или чтения из файла.
Современные файловые системы поддерживают и другие типы файлов, такие как символьные связи, именованные конвейеры, отображаемые в память файлы.
Иерархическая структура
файловой системы
Большинство файловых систем имеет иерархическую структуру, в которой уровни создаются за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня.
Граф, описывающий иерархию каталогов, может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в один каталог, и сеть — если файл может входить сразу в несколько каталогов. Например, в MS-DOS и Windows каталоги образуют древовидную структуру, а в UNIX — сетевую. В древовидной структуре каждый файл является листом. Каталог самого верхнего уровня называется корневым каталогом, или корнем (root).
При такой организации пользователь освобожден от запоминания имен всех файлов, ему достаточно примерно представлять, к какой группе может быть отнесен тот или иной файл, чтобы путем последовательного просмотра каталогов найти его. Иерархическая структура удобна для многопользовательской работы: каждый пользователь со своими файлами локализуется в своем каталоге или поддереве каталогов, и вместе с тем все файлы в системе логически связаны.
Частным случаем иерархической структуры является одноуровневая организация, когда все файлы входят в один каталог. в начало
56.
Физическая
организация и адресация файлов.
Важным компонентом физической организации файловой системы является физическая организация файла, то есть способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
· скорость доступа к данным;
· объем адресной информации файла;
· степень фрагментированности дискового пространства;
· максимально возможный размер файла.
Непрерывное размещение — простейший вариант физической организации, при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти. Основным достоинством этого метода является высокая скорость доступа, так как затраты на поиск и считывание кластеров файла минимальны. Также минимален объем адресной информации — достаточно хранить только номер первого кластера и объем файла. Данная физическая организация максимально возможный размер файла не ограничивает. Однако этот вариант имеет существенные недостатки, которые затрудняют его применимость на практике. Какого размера должна быть непрерывная область, выделяемая файлу, если файл при каждой модификации может увеличить свой размер? Еще более серьезной проблемой является фрагментация.
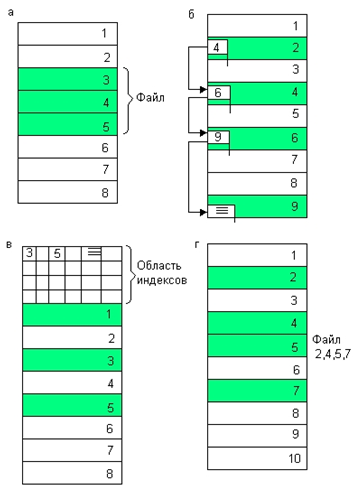
Рисунок 29. Физическая организация файла непрерывное размещение
(а); связанный список кластеров (б); связанный список индексов (в); перечень
номеров кластеров (г)
Следующий способ физической организации — размещение файла в виде связанного списка кластеров дисковой памяти. При таком способе в начале каждого кластера содержится указатель на следующий кластер. В этом случае адресная информация минимальна: расположение файла может быть задано одним числом — номером первого кластера. Недостатком является сложность реализации доступа к произвольно заданному месту файла — чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров.
Популярным способом, применяемым, например, в файловой системе FAT, является использование связанного списка индексов. Этот способ является некоторой модификацией предыдущего. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент — индекс. Индексы располагаются в отдельной области диска — в MS-DOS это таблица FAT (File Allocation Table), занимающая один кластер. Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру М следующего кластера данного файла, либо принимает специальное значение, являющееся признаком того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер.
При такой физической организации сохраняются все достоинства предыдущего способа: минимальность адресной информации, отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами. Во-первых, для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера. Во-вторых, данные файла заполняют кластер целиком, а значит, имеют объем, равный степени двойки.
Последний подход с некоторыми модификациями используется в традиционных файловых системах ОС UNIX s5 и ufs1. Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным.
В стандартной на сегодняшний день для UNIX файловой системе ufs используется следующая схема адресации кластеров файла. Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт. Если размер файла меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт (максимальный размер кластера, поддерживаемого в ufs), то таким образом можно адресовать файл размером до 8192x12 - 98 304 байт.
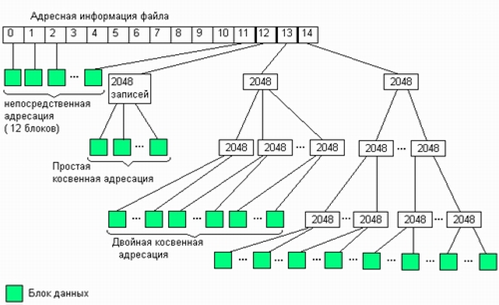
Рисунок 30. Схема адресации файловой системы ufs
Если размер файла превышает 12 кластеров, то следующее 13-е поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров файла. При размере в 8 Кбайт кластер, на который указывает 13-й элемент, может содержать 2048 номеров следующих кластеров данных файла и размер файла может возрасти до 8192х(12+2048)=16 875 520 байт.
Если размер файла превышает 12+2048— 2060 кластеров, то используется 14-е поле, в котором находится номер кластера, содержащего 2048 номеров кластеров, каждый из которых хранят 2048 номеров кластеров данных файла. Здесь применяется уже двойная косвенная адресация. С ее помощью можно адресовать кластеры в файлах, содержащих до 8192х(12+2048+20482) = 3,43766x10'° байт.
И наконец, если файл включает более 12+2048+20482= 4 196 364 кластеров, то используется последнее 15-е поле для тройной косвенной адресации, что позволяет задать адрес файла, имеющего следующий максимальный размер: 8192х(12+2048+20482+20483)=7,0403х1013 байт.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая отрезком (run), или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла и объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5. в начало
57.
FAT. Структура
тома. Формат записи каталога. FAT12, FAT16, FAT32.
Логический
раздел, отформатированный под файловую систему FAT, состоит из следующих
областей.
ñ Загрузочный сектор содержит
программу начальной загрузки операционной системы. Вид этой программы зависит
от типа операционной системы, которая будет загружаться из этого раздела.
ñ Основная копия FA Т содержит
информацию о размещении файлов и каталогов на диске.
ñ Резервная копия FAT.
ñ Корневой каталог занимает
фиксированную область размером в 32 сектора (16 Кбайт), что позволяет хранить
512 записей о файлах и каталогах, так как каждая запись каталога состоит из 32
байт.
ñ Область данных предназначена для
размещения всех файлов и всех каталогов, кроме корневого каталога.
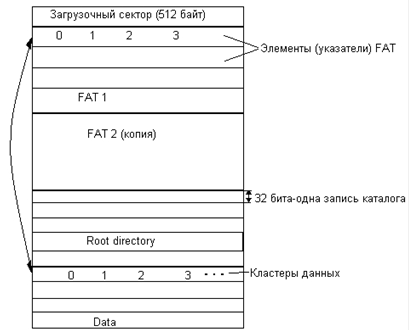
Файловая
система FAT поддерживает всего два типа файлов: обычный файл и каталог.
Файловая система распределяет память только из области данных, причем
использует в качестве минимальной единицы дискового пространства кластер.
Таблица
FAT состоит из массива индексных указателей, количество которых равно
количеству кластеров области данных. Между кластерами и индексными указателями
имеется взаимно однозначное соответствие — нулевой указатель соответствует
нулевому кластеру и т. д.
Индексный
указатель может принимать следующие значения, характеризующие состояние
связанного с ним кластера:
ñ кластер свободен (не
используется);
ñ кластер используется файлом и не
является последним кластером файла; в этом случае индексный указатель содержит
номер следующего кластера файла;
ñ последний кластер файла; О
дефектный кластер; а резервный кластер.
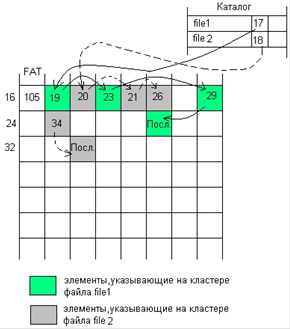
Таблица
FAT является общей для всех файлов раздела. В исходном состоянии (после
форматирования) все кластеры раздела свободны и все индексные указатели (кроме
тех, которые соответствуют резервным и дефектным блокам) принимают значение
«кластер свободен». При размещении файла ОС просматривает FAT, начиная с
начала, и ищет первый свободный индексный указатель. После его обнаружения в
поле записи каталога «номер первого кластера» фиксируется номер этого
указателя. В кластер с этим номером записываются данные файла, он становится
первым кластером файла. Если файл умещается в одном кластере, то в указатель,
соответствующий данному кластеру, заносится специальное значение «последний
кластер файла». Если же размер файла больше одного кластера, то ОС продолжает
просмотр FAT и ищет следующий указатель на свободный кластер. После его
обнаружения в предыдущий указатель заносится номер этого кластера, который
теперь становится следующим кластером файла. Процесс повторяется до тех пор,
пока не будут размещены все данные файла. Таким образом создается связный
список всех кластеров файла.
Размер
таблицы FAT и разрядность используемых в ней индексных указателей определяется
количеством кластеров в области данных. Для уменьшения потерь из-за
фрагментации желательно кластеры делать небольшими, а для сокращения объема
адресной информации и повышения скорости обмена наоборот — чем больше, тем
лучше. При форматировании диска под файловую систему FAT обычно выбирается
компромиссное решение и размеры кластеров выбираются из диапазона от 1 до 128
секторов, или от 512 байт до 64 Кбайт.
Очевидно,
что разрядность индексного указателя должна быть такой, чтобы в нем можно было
задать максимальный номер кластера для диска определенного объема. Существует
несколько разновидностей FAT, отличающихся разрядностью индексных указателей,
которая и используется в качестве условного обозначения: FAT12, FAT16 и FAT32.
В файловой системе FAT12 используются 12-разрядные указатели, что позволяет
поддерживать до 4096 кластеров в области данных диска1, в FAT16 — 16-разрядные
указатели для 65 536 кластеров и в FAT32 — 32-разрядные для более чем 4
миллиардов кластеров.
Таблица
FAT при фиксированной разрядности индексных указателей имеет переменный размер,
зависящий от объема области данных диска.
При
удалении файла из файловой системы FAT в первый байт соответствующей записи
каталога заносится специальный признак, свидетельствующий о том, что эта запись
свободна, а во все индексные указатели файла заносится признак «кластер
свободен». Остальные данные в записи каталога, в том числе номер первого
кластера файла, остаются нетронутыми, что оставляет шансы для восстановления
ошибочно удаленного файла. Существует большое количество утилит для
восстановления удаленных файлов FAT, выводящих пользователю список имен
удаленных файлов с отсутствующим первым символом имени, затертым после освобождения
записи. Очевидно, что надежно можно восстановить только файлы, которые были
расположены в последовательных кластерах диска, так как при отсутствии связного
списка выявить принадлежность произвольно расположенного кластера удаленному
файлу невозможно (без анализа содержимого кластеров, выполняемого пользователем
«вручную»).
Резервная
копия FAT всегда синхронизируется с основной копией при любых операциях с
файлами, поэтому резервную копию нельзя использовать для отмены ошибочных
действий пользователя, выглядевших с точки зрения системы вполне корректными.
Резервная копия может быть полезна только в том случае, когда секторы основной
памяти оказываются физически поврежденными и не читаются.
Используемый
в FAT метод хранения адресной информации о файлах не отличается большой
надежностью — при разрыве списка индексных указателей в одном месте, например
из-за сбоя в работе программного кода ОС по причине внешних электромагнитных
помех, теряется информация обо всех последующих кластерах файла. в начало
58.
Файловая система
HPFS.
HPFS
(аббр. От англ.High
Perfomance
File System) — файловая система,
разработанная специалистами Microsoft и IBM.
Впервые
поддержка HPFS появилась в операционной системе OS/2 версии 1.2.
С тех пор штатная поддержка HPFS присутствует во всех версиях OS/2. В Windows
NTподдержка HPFS существовала до версии 3.51 включительно. Впоследствии Microsoft
отказалась от HPFS в пользу собственной файловой системы NTFS, при разработке
которой был учтён опыт создания HPFS.
Диск
в HPFS делится на сектора фиксированного размера (512 байт в текущей
реализации, при этом номер сектора или их количество кодируются во внутренних
структурах как 4-байтовое беззнаковое целое, что позволяет адресовать диски
размером до 232 * 512 = 2 терабайта).
В
начале диска расположены несколько управляющих блоков:
1. Загрузочный сектор DOS-овского
вида.
2. SuperBlock содержит информацию о
геометрии диска, указатели на битовые карты (т.н. битмапы, от англ. bitmaps) свободного пространства,
указатель на корневой каталог, размер дисковой полосы, номер полосы с
каталогами, указатель на список сбойных блоков и т.п. SuperBlock также содержит
дату последнего запускаCHKDSK. Обычно изменяют SuperBlock только программы
CHKDSK и FORMAT (англ.).
3. SpareBlock содержит
указатели на пул HOTFIX-areas, пул Fault-Tolerance областей (только HPFS386
использует Fault-Tolerance), пул блоков для операций на почти переполненном
диске и другие указатели, флаги и дескрипторы.
4. Область начальной загрузки.
5. Область секторов используемых
(временно) для выполнения операций требующих дополнительную дисковую память.
Эта область например, иногда задействуется при переименовании файла на
заполненном диске.
6. Другие области.
Для
определения того, свободен сектор или занят, HPFS использует битовые
карты, в которых каждый бит соответствует одному сектору. Если бит содержит 1,
это означает, что сектор занят, иначе он свободен. Если бы на весь диск была
только одна битовая карта, то для её подкачки приходилось бы перемещать головки
чтения/записи в среднем через половину диска. Чтобы избежать этого, HPFS
разбивает диск на «полосы» (или группы, от англ. bands) длиной по 8 мегабайт и хранит
битмапы свободных секторов в начале или конце каждой полосы. При этом битмапы соседних
полос располагаются рядом:
±------------ 16MB -----------+ *** — Use/Free sector bitmap.
| |
±-|-------------±----------±--|--±-------------±--------------+
|***
Полоса 0 | Полоса 1 ***|*** Полоса 2
| Полоса 3 ***|
±---------------±-------------±----------------±--------------+
0MB
8MB
16MB
24MB
32MB
Расстояние
между двумя битмапами равно 16MB. Размер полосы (8MB) может быть изменён в
следующих версиях HPFS, так как на него нет прямых завязок. HPFS определяет
размер полосы при чтении управляющих блоков с диска во время выполнения
операции FSHelperAttach.
Размер
битмапа равен 2K (8MB/512/8 = 2K).
Полоса,
находящаяся в центре диска, используется для хранения каталогов. Эта полоса
называется Directory Band. Однако, если она будет полностью заполнена, HPFS
начнёт располагать каталоги файлов в других полосах.
Файлы
и каталоги в HPFS базируются на фундаментальном объекте, называемом FNode.
Каждая FNode занимает один сектор и в HPFS всегда располагается поблизости от
своего файла или каталога (обычно непосредственно перед файлом или каталогом). FNode
содержит длину и первые 15 символов имени файла, статистику по доступу к файлу,
внутреннюю информацию, расширенные атрибуты и ACL (или
только часть, если они очень большие), ассоциативную информацию о расположении
и подчинении файла и т. д.
Имена
файлов и каталогов при полной подстановке (от корня) не должны превышать 260
символов, при этом каждая компонента пути не должна быть длиннее 255 символов.
Последовательности
конечных пробелов игнорируются, если на конце файла стоит точка, то она тоже
игнорируется.
С
точки зрения размещения, файлы, каталоги и их расширенные атрибуты (если они не
помещаются в FNode) рассматриваются HPFS как наборы экстентов. Экстент —
это часть файла, лежащая в последовательных секторах. Каждый экстент
описывается двумя числами: номером первого сектора и длиной (в секторах). Два последовательных
экстента всегда объединяются HPFS в один. Минимальный размер экстента —
один сектор. Так как расстояние между соседними битмапами свободных секторов
равно 16 МБ, то и размер максимального экстента равен 16 МБ.
Реальные
файлы состоят из 1-3 экстентов.
Максимальный
размер файла в HPFS сейчас 2 ГБ, однако он обусловлен только размером поля под
размер файла и файловым указателем (4 байта) в самой OS/2 и её API. Это не
предел HPFS. Следует помнить, что в HPFS отсутствует понятие кластера, файл может
занимать 1, 2, 3, 4 или любое другое количество секторов.
Каталоги
в HPFS, как и в FAT, образуют древовидную структуру. Но при этом внутри
каталога HPFS строит сбалансированное B*-дерево на основе имён файлов
дляй экстент опи быстрого поиска файла по имени внутри каталога. Например, если
каталог содержит 4096 файлов, FAT будет читать в среднем 64 сектора для поиска
файла внутри каталога, а HPFS считает 2-4 сектора и найдёт файл.
Размер
блока, в терминах которых выделяются каталоги, равен 2KB в текущей версии HPFS.
Размер записи, описывающей файл, зависит от размера имени файла. Если имя
занимает 13 байт, то 2-килобайтовый блок вмещает 41 описатель файлов. Блоки
прошиты списком (как и описатели экстентов) для облегчения последовательного
обхода.
При
переименовании файла может возникнуть перебалансировка дерева. Эта операция
может потребовать выделения дополнительных блоков на заполненном диске. В этом
случае блоки берутся из специального пула, указатель на который лежит в SpareBlock.
в начало
59.
UFS : структура
тома, адресация файлов, каталоги, индексные дескрипторы.
Cистема
ufs является развитием системы s5. Файловая система ufs расширяет возможности s5
по поддержке больших дисков и файлов, а также повышает ее надежность.
Раздел
диска, где размещается файловая система, делится на четыре области:
ñ загрузочный блок;
ñ суперблок (superblock) содержит
самую общую информацию о файловой системе: размер файловой системы, размер
области индексных дескрипторов, число индексных дескрипторов, список свободных
блоков и список свободных индексных дескрипторов, а также другую
административную информацию;
ñ область индексных дескрипторов (inode
list), порядок расположения индексных дескрипторов в которой соответствует их
номерам;
ñ область данных, в которой расположены
как обычные файлы, так и файлы-каталоги, в том числе и корневой каталог;
специальные файлы представлены в файловой системе только записями в
соответствующих каталогах и индексными дескрипторами специального формата, но
места в области данных не занимают.
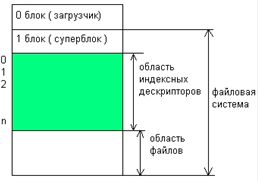
Основной
особенностью является отделение имени файла от его характеристик, хранящихся в
отдельной структуре, называемой индексным дескриптором (inode). Индексный
дескриптор в s5 имеет размер 64 байта и содержит данные о типе файла, адресную информацию,
привилегии доступа к файлу и некоторую другую информацию:
ñ идентификатор владельца файла;
ñ тип файла; файл может быть файлом
обычного типа, каталогом, специальным файлом, а также конвейером или символьной
связью;
ñ права доступа к файлу;
ñ временные характеристики: время
последней модификации файла, время последнего обращения к файлу, время
последней модификации индексного дескриптора;
ñ число ссылок на данный индексный
дескриптор, равный количеству псевдонимов файла;
ñ адресная информация (структура
адреса рассмотрена выше в разделе «Физическая организация и адресация файла»);
ñ размер файла в байтах.
Каждый
индексный дескриптор имеет номер, который одновременно является уникальным
именем файла. Индексные дескрипторы расположены в особой области диска в строгом
соответствии со своими номерами. Соответствие между полными символьными именами
файлов и их уникальными именами устанавливается с помощью иерархии каталогов.
Система ведет список номеров свободных индексных дескрипторов. При создании
файла ему выделяется номер из этого списка, а при уничтожении файла номер его
индексного дескриптора возвращается в список.
Запись
о файле в каталоге состоит всего из двух полей: символьного имени файла и
номера индексного дескриптора.
Файловая
система не накладывает особых ограничений на размер корневого каталога, так как
он расположен в области данных и может увеличиваться как обычный файл.
Доступ
к файлу осуществляется путем последовательного просмотра всей цепочки
каталогов, входящих в полное имя файла, и соответствующих им индексных
дескрипторов. Поиск завершается после получения всех характеристик из
индексного дескриптора заданного файла.
Эта
процедура требует в общем случае нескольких обращений к диску, пропорционально
числу составляющих в полном имени файла. Для уменьшения среднего времени
доступа к файлу его дескриптор копируется в специальную системную область
оперативной памяти. Копирование индексного дескриптора входит в процедуру
открытия файла.
Физическая
организация файловой системы ufs отличается от описанной физической организации
файловой системы s5 тем, что раздел состоит из повторяющейся несколько раз
последовательности областей «загрузчик—суперблок—блок группы цилиндров—область
индексных дескрипторов».
![]()

В
этих повторяющихся последовательностях областей суперблок является резервной
копией основной первой копии суперблока. При повреждении основной копии
суперблока может быть использована резервная копия суперблока. Области же блока
группы цилиндров и индексных дескрипторов содержат индивидуальные для каждой
последовательности значения. Блок группы цилиндров описывает количество
индексных дескрипторов и блоков данных, расположенных на данной группе
цилиндров диска. Такая группировка делается для ускорения доступа, чтобы
просмотр индексных дескрипторов и данных файлов, описываемых этими дескрипторами,
не приводил к слишком большим перемещениям головок диска.
Кроме
того, в ufs имена файлов могут иметь длину до 255 символов (кодировка ASCII, по
одному байту на символ), в то время как в s5 длина имени не может превышать 14
символов. в
начало
60.
NTFS: структура
тома.
Файловая
система NTFS была разработана в качестве основной файловой системы для ОС Windows
NT в начале 90-х годов с учетом опыта разработки файловых систем FAT и HPFS
(основная файловая система для OS/2), а также других существовавших в то время
файловых систем. Основными отличительными свойствами NTFS являются:
ñ поддержка больших файлов и
больших дисков объемом до 2 байт;
ñ восстанавливаемость после сбоев и
отказов программ и аппаратуры управления дисками;
ñ высокая скорость операций, в том
числе и для больших дисков;
ñ низкий уровень фрагментации, в
том числе и для больших дисков;
ñ гибкая структура, допускающая
развитие за счет добавления новых типов записей и атрибутов файлов с
сохранением совместимости с предыдущими версиями ФС;
ñ устойчивость к отказам дисковых
накопителей;
ñ поддержка длинных символьных
имен;
ñ контроль доступа к каталогам и
отдельным файлам.
Структура тома NTFS
Все
пространство тома NTFS представляет собой либо файл, либо часть файла. Основой
структуры тома NTFS является главная таблица файлов (Master File Table, MFT),
которая содержит по крайней мере одну запись для каждого файла тома, включая
одну запись для самой себя. Каждая запись MFT имеет фиксированную длину,
зависящую от объема диска, — 1,2 или 4 Кбайт. Для большинства дисков,
используемых сегодня, размер записи MFT равен 2 Кбайт, который мы далее будет
считать размером записи по умолчанию.
Все
файлы на томе NTFS идентифицируются номером файла, который определяется
позицией файла в MFT.
Весь
том NTFS состоит из последовательности кластеров, что отличает эту файловую
систему от рассмотренных ранее, где на кластеры делилась только область данных.
Порядковый номер кластера в томе NTFS называется логическим номером кластера {Logical
Cluster Number, LCN). Файл NTFS также состоит из последовательности кластеров,
при этом порядковый номер кластера внутри файла называется виртуальным номером
кластера (Virtual Cluster Number, VCN).
Базовая
единица распределения дискового пространства для файловой системы NTFS —
непрерывная область кластеров, называемая отрезком. В качестве адреса отрезка NTFS
использует логический номер его первого кластера, а также количество кластеров
в отрезке k, то есть пара (LCN, k). Таким образом, часть файла, помещенная в
отрезок и начинающаяся с виртуального кластера VCN, характеризуется адресом,
состоящим из трех чисел: (VCN, LCN, k).
Для
хранения номера кластера в NTFS используются 64-разрядные указатели, что дает
возможность поддерживать тома и файлы размером до 264 кластеров. При
размере кластера в 4 Кбайт это позволяет использовать тома и файлы, состоящие
из 64 миллиардов килобайт.
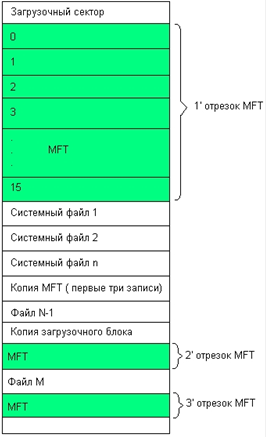
![]()
Далее
располагается первый отрезок MFT, содержащий 16 стандартных, создаваемых при
форматировании записей о системных файлах NTFS. Назначение этих файлов описано
в показанной ниже таблице MFT.
|
Номер
записи |
Системный
файл |
Имя
файла |
Назначение
файла |
|
0 |
Главная
таблица файлов |
$Mft |
Содержит
полный список файлов тома NTFS |
|
1 |
Копия
главной таблицы файлов |
SMftMirr |
Зеркальная
копия первых трех записей MFT |
|
2 |
Файл
журнала |
SLogFile |
Список
транзакций, который используется для восстановления файловой системы после
сбоев |
|
3 |
Том |
SVolume |
Имя
тома, версия NTFS и другая информация о томе |
|
4 |
Таблица
определения атрибутов |
SAttrDef |
Таблица
имен, номеров и описаний атрибутов |
|
5 |
Индекс
корневого каталога |
$. |
Корневой
каталог |
|
6 |
Битовая
карта кластеров |
SBitmap |
Разметка
использованных кластеров тома |
|
7 |
Загрузочный
сектор раздела |
SBoot |
Адрес
загрузочного сектора раздела |
|
8 |
Файл
плохих кластеров |
SBadClus |
Файл,
содержащий список всех обнаруженных на томе плохих кластеров |
|
9 |
Таблица
квот |
SQuota |
Квоты
используемого пространства на диске для каждого пользователя |
|
10 |
Таблица
преобразования регистра символов |
SUpcase |
Используется
для преобразования регистра символов для кодировки Unicode |
|
11-15 |
Зарезервированы
для будущего использования |
|
|
В
NTFS файл целиком размещается в записи таблицы MFT, если это позволяет сделать
его размер. В том же случае, когда размер файла больше размера записи MFT, в
запись помещаются только некоторые атрибуты файла, а остальная часть файла
размещается в отдельном отрезке тома
(или нескольких отрезках). Часть файла, размещаемая в записи MFT, называется
резидентной частью, а остальные части — нерезидентными. Адресная информация об
отрезках, содержащих нерезидентные части файла, размещается в атрибутах резидентной
части.
Некоторые
системные файлы являются полностью резидентными, а некоторые имеют и
нерезидентные части, которые располагаются после первого отрезка MFT. Нулевая
запись MFT содержит описание самой MFT, в том числе и такой ее важный атрибут,
как адреса всех ее отрезков. После форматирования MFT состоит из одного
отрезка, но после создания первого же несистемного файла для хранения его
атрибутов требуется еще один отрезок, так как изначально непрерывная
последовательность кластеров MFT уже завершена системными файлами.
Из
приведенного описания видно, что сама таблица MFT рассматривается как файл, к
которому применим метод размещения в томе в виде набора произвольно
расположенных нескольких отрезков. в начало
61.
NTFS: типы
файлов, организация каталогов.
Структура файлов NTFS
Каждый
файл и каталог на томе NTFS состоит из набора атрибутов. Важно отметить, что
имя файла и его данные также рассматриваются как атрибуты файла, то есть в
трактовке NTFS кроме атрибутов у файла нет никаких других компонентов.
Каждый
атрибут файла NTFS состоит из полей: тип атрибута, длина атрибута, значение
атрибута и, возможно, имя атрибута. Тип атрибута, длина и имя образуют
заголовок атрибута.
Имеется
системный набор атрибутов, определяемых структурой тома NTFS. Системные атрибуты
имеют фиксированные имена и коды их типа, а также определенный формат. Могут
применяться также атрибуты, определяемые пользователями. Их имена, типы и
форматы задаются исключительно пользователем. Атрибуты файлов упорядочены по
убыванию кода атрибута, причем атрибут одного и того же типа может повторяться
несколько раз. Существуют два способа хранения атрибутов файла — резидентное
хранение в записях таблицы MFT и нерезидентное хранение вне ее, во внешних
отрезках. Таким образом, резидентная часть файла состоит из резидентных
атрибутов, а нерезидентная — из нерезидентных атрибутов. Сортировка может осуществляться
только по резидентным атрибутам.
Системный
набор включает следующие атрибуты:
ñ Attribute List (список
атрибутов) — список атрибутов, из которых состоит файл; содержит ссылки на
номер записи MFT, где расположен каждый атрибут; этот редко используемый
атрибут нужен только в том случае, если атрибуты файла не умещаются в основной
записи и занимают дополнительные записи MFT;
ñ File Name (имя файла)
— этот атрибут содержит длинное имя файла в формате Unicode, а также номер
входа в таблице MFT для родительского каталога; если этот файл содержится в
нескольких каталогах, то у него будет несколько атрибутов типа File Name;
этот атрибут всегда должен быть резидентным;
ñ MS-DOS Name (имя MS-DOS)
— этот атрибут содержит имя файла в формате 8.3;
ñ Version (версия) —
атрибут содержит номер последней версии файла;
ñ Security Descriptor (дескриптор
безопасности) — этот атрибут содержит информацию о защите файла: список прав
доступа ACL (права доступа к файлу рассматриваются ниже в разделе «Контроль
доступа к файлам») и поле аудита, которое определяет, какого рода операции над
этим файлом нужно регистрировать;
ñ Volume Version (версия
тома) — версия тома, используется только в системных файлах тома;
ñ Volume Name (имя тома)
— имя тома;
ñ Data (данные) —
содержит обычные данные файла;
ñ MFT bitmap (битовая
карта MFT) — этот атрибут содержит карту использования блоков на томе;
ñ Index Root (корень
индекса) — корень В-дерева, используемого для поиска файлов в каталоге;
ñ Index Allocation
(размещение индекса) — нерезидентные части индексного списка В-дерева;
ñ Standard Information (стандартная
информация) — этот атрибут хранит всю остальную стандартную информацию о файле,
которую трудно связать с каким-либо из других атрибутов файла, например, время
создания файла, время обновления и другие.
Файлы
NTFS в зависимости от способа размещения делятся на небольшие, большие, очень
большие и сверхбольшие.
Небольшие
файлы (small). Если файл имеет небольшой размер, то он может целиком
располагаться внутри одной записи MFT, имеющей, например, размер 2 Кбайт.
Небольшие файлы NTFS состоят по крайней мере из следующих атрибутов:
ñ стандартная информация
(SI — standard information);
ñ имя файла (FN —
file name);
ñ данные (Data);
ñ дескриптор безопасности (SD
— security descriptor).
Из-за
того что файл может иметь переменное количество атрибутов, а также из-за
переменного размера атрибутов нельзя наверняка утверждать, что файл уместится
внутри записи. Однако обычно файлы размером менее 1500 байт помещаются внутри
записи MFT (размером 2 Кбайт).
![]()
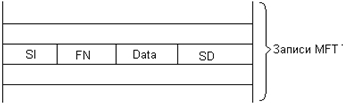
Большие
файлы (large). Если данные файла не помещаются в одну запись МFТ, то этот факт
отражается в заголовке атрибута Data, который содержит признак того, что
этот атрибут является нерезидентным, то есть находится в отрезках вне таблицы MFT.
В этом случае атрибут Data содержит адресную информацию (LCN, VCN, k)
каждого отрезка данных.
![]()
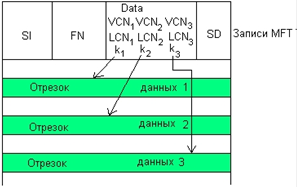
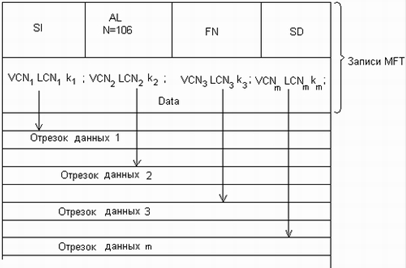
Сверхбольшие
файлы (extremely huge). Для сверхбольших файлов в атрибуте Attribute
List можно указать несколько атрибутов, расположенных в дополнительных
записях MFT. Кроме того, можно использовать двойную косвенную адресацию, когда
нерезидентный атрибут будет ссылаться на другие нерезидентные атрибуты.
Очень
большие файлы (huge). Если файл настолько велик, что его атрибут данных,
хранящий адреса нерезидентных отрезков данных, не помещается в одной записи, то
этот атрибут помещается в другую запись MFT, а ссылка на такой атрибут
помещается в основную запись файла. Эта ссылка содержится в атрибуте Attribute
List. Сам атрибут данных по-прежнему содержит адреса нерезидентных отрезков
данных.
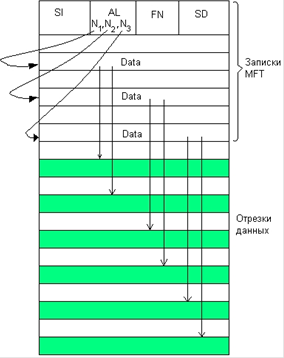
Каталоги NTFS
Каждый
каталог NTFS представляет собой один вход в таблицу MFT, который содержит
атрибут Index Root. Индекс содержит список файлов, входящих в каталог. Индексы
позволяют сортировать файлы для ускорения поиска, основанного на значении
определенного атрибута. Обычно в файловых системах файлы сортируются по имени. NTFS
позволяет использовать для сортировки любой атрибут, если он хранится в
резидентной форме.
Имеются
две формы хранения списка файлов.
Небольшие
каталоги (small indexes). Если количество файлов в каталоге невелико,
то список файлов может быть резидентным в записи в MFT, являющейся каталогом.
Для резидентного хранения списка используется единственный атрибут — Index
Root. Список файлов содержит значения атрибутов файла. По умолчанию — это
имя файла, а также номер записи MTF, содержащей начальную запись файла.
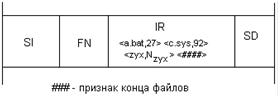
Большие
каталоги (large indexes). По мере того как каталог растет, список файлов
может потребовать нерезидентной формы хранения. Однако начальная часть списка
всегда остается резидентной в корневой записи каталога в таблице MFT. Имена
файлов резидентной части списка файлов являются узлами так называемого В-дерева
(двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их
поиска используется специальный атрибут Index Allocation, представляющий собой
адреса отрезков, хранящих остальные части списка файлов каталога. Одни части
списков являются листьями дерева, а другие являются промежуточными узлами, то
есть содержат наряду с именами файлов атрибут Index Allocation, указывающий
на списки файлов более низких уровней.
Узлы
двоичного дерева делят весь список файлов на несколько групп. Имя каждого
файла-узла является именем последнего файла в соответствующей группе.
Считается, что имена файлов сравниваются лексикографически, то есть сначала
принимаются во внимание коды первых символов двух сравниваемых имен, при этом
имя считается меньшим, если код его первого символа имеет меньшее
арифметическое значение, при равенстве кодов первых символов сравниваются коды
вторых символов имен и т. д.
Поиск
в каталоге уникального имени файла, которым в NTFS является номер основной
записи о файле в MFT, по его символьному имени происходит следующим образом.
Сначала искомое символьное имя сравнивается с именем первого узла в резидентной
части индекса. Если искомое имя меньше, то это означает, что его нужно искать в
первой нерезидентной группе, для чего из атрибута Index Allocation извлекается
адрес отрезка (VCNj, LCN^ K!), хранящего имена файлов первой группы. Среди имен
этой группы поиск осуществляется прямым перебором имен и сравнением до полного
совпадения всех символов искомого имени с хранящимся в каталоге именем. При
совпадении из каталога извлекается номер основной записи о файле в MFT и
остальные характеристики файла берутся уже оттуда.
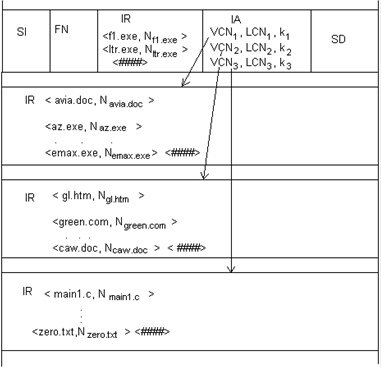
Если
же искомое имя больше имени первого узла резидентной части индекса, то его
сравнивают с именем второго узла, и если искомое имя меньше, то описанная
процедура применяется ко второй нерезидентной группе имен, и т. д.
В
результате вместо перебора большого количества имен выполняется сравнение с
гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Если
одна из групп каталога становится слишком большой, то ее также делят на группы,
последние имена каждой новой группы оставляют в исходном нерезидентном атрибуте
Index Root, а все остальные имена новых групп переносят в новые нерезидентные
атрибуты типа Index Root (на рисунке этот случай не показан). К
исходному нерезидентному атрибуту Index Rootдобавляется атрибут размещения
индекса, указывающий на отрезки индекса новых групп. Если теперь при поиске искомого
имени в нерезидентной части индекса первого уровня какое-либо сравнение
показывает, что искомое имя оказывается меньше, чем одно из хранящихся там
имен, то это говорит о том, что в данном атрибуте точного сравнения имени уже
быть не может и нужно перейти к подгруппе имен следующего уровня дерева.
в начало
62.
Файловые
операции. Процедура открытия файла.
Открытие файла
Системный
вызов open в ОС UNIX работает с двумя аргументами: символьным именем
открываемого файла и режимом открытия файла. Режим открытия говорит системе,
какие операции будут выполняться над файлом в последовательности операций до
закрытия файла по системному вызову close, например: только чтение, только
запись или чтение и запись.
При
открытии файла ОС сначала выполняет преобразование первого аргумента системного
вызова, то есть символьного имени файла, в его уникальное числовое имя, которым
в традиционных файловых системах UNIX является номер индексного дескриптора.
Эта процедура была рассмотрена выше при описании файловой системы s5.
По
номеру индексного дескриптора inode файловая система находит нужную
запись на диске и копирует из нее характеристики файла в оперативную память.
Для
хранения копии индексного дескриптора используются буферные области системного
виртуального пространства. Характеристики индексного дескриптора, перенесенные
в оперативную память, помещаются в структуру так называемого виртуального
дескриптора vnode (virtual node). Структура vnode включает
поля индексного дескриптора файла inode, а также несколько перечисленных
ниже дополнительных полей, полезных при выполнении операций с файлом.
ñ Состояние индексного
дескриптора в памяти, отражающее:
ñ заблокирован ли файл;
ñ ждет ли снятия блокировки с
файла какой-либо процесс;
ñ отличается ли представление
характеристик файла в памяти от своей дисковой копии в результате изменения
содержимого индексного дескриптора;
ñ отличается ли представление
файла в памяти от своей дисковой копии в результате изменения содержимого
файла;
ñ является ли файл точкой
монтирования.
ñ Логический номер устройства
файловой системы, содержащей файл.
ñ Номер индексного
дескриптора. В дисковом индексном дескрипторе это поле отсутствует, так как
номер определяется положением дескриптора относительно начала области индексных
дескрипторов.
ñ Счетчик ссылок на данную
структуру vnode.
С
одним и тем же файлом в какой-то период времени могут работать различные
процессы, но операционная система не создает для каждого процесса отдельную
копию структуры vnode, а для каждого файла, с которым в данный момент
работает хотя бы один процесс, хранит ровно одну копию виртуального
дескриптора. При очередном открытии файла ОС проверяет, имеется ли в системной
памяти структура vnode открываемого файла, и если имеется, то счетчик
ссылок на нее увеличивается на единицу. При очередном закрытии этого файла
счетчик ссылок уменьшается на единицу, и если он становится равным 0, то буфер,
хранящий данный vnode, считается свободным.
Использование
единственной копии характеристик файла и некоторых характеристик файловых
операций, общих для всех работающих с файлом процессов, экономит системную
память. Тем не менее существуют характеристики, индивидуальные для каждого
процесса, выполняющего некоторую последовательность операций с определенным файлом.
Для их хранения в UNIX используется структура типа file, которая так же,
как и vnode, хранится в системной области памяти.
При
каждом открытии процессом файла ОС проверяет права пользовательского процесса
на выполнение запрошенной операции с файлом и, если проверка прошла успешно,
создает в системной области памяти новую структуру f i I e, которая описывает
как открытый файл, так и операции, которые процесс собирается производить с
файлом (например, чтение).
Структура
file содержит такие поля, как:
ñ признак режима открытия
(только для чтения, для чтения и записи и т. п.);
ñ указатель на структуру
vnode;
ñ текущее смещение в файле
(переменная offset) при операциях чтения/записи; О счетчик ссылок на данную
структуру;
ñ указатель на структуру,
содержащую права процесса, открывшего файл (эта структура находится в
дескрипторе процесса);
ñ указатели на предыдущую и
последующую структуры file, связывающие все такие структуры в двойной список.
Переменная offset,
хранящаяся в структуре file, позволяет ОС запоминать текущее положение
условного указателя в последовательности байт файла. При открытии файла эта
переменная указывает на начальный или конечный байт файла в зависимости от
заданного режима открытия. После выполнения операций чтения или записи
указатель сдвигается на то количество байт, которое было прочитано или записано
в результате операции. Следующая операция застает указатель в том состоянии, в
котором его оставила предыдущая операция. Прикладной программист может явно
управлять положением указателя с помощью системного вызова lseek, который
будет рассмотрен ниже.
При
каждом новом открытии какого-либо файла ОС создает новую структуру file и
помещает ее в дважды связанный список (рис. 7.27). Обычно под хранение
структур file в системной области отводится ограниченная область,
поэтому общее количество открытых файлов всеми процессами в любой момент
ограничено.
После
создания структуры file операционная система помещает указатель на
нее в таблицу открытых файлов процесса, которая находится в контексте процесса.
Если процесс несколько раз открывает один и тот же файл, то структура file создается
для каждой операции открытия. Так как контекст процесса-родителя в UNIX
наследуется процессом-потомком, то потомок наследует и указатели на все
открытые родителем файлы, получая возможность выполнять над ними операции.
Системный
вызов open возвращает в пользовательский процесс дескриптор файла,
который представляет собой номер записи в таблице открытых файлов процесса.
Дескриптор файла имеет локальное значение только для того процесса, который
открыл файл, для разных процессов одно и то же значение дескриптора указывает
на разные операции, в общем случае над разными файлами.
После
открытия файла его дескриптор используется во всех дальнейших операциях с
файлом вплоть до явного закрытия файла. Таким образом, дескриптор файла
является временным уникальным именем, но не файла, а определенной
последовательности операций с этим файлом.
Для
открытия файла /bin/prog1.ехе в режиме «только для чтения» прикладной
программист может использовать следующее выражение на языке С:
fd
=open("'/bin/progl.exe". 0_RDONLY):
Здесь
fd — это целочисленная переменная, сохраняющая значение дескриптора открытого
файла. Ее значение должно использоваться в операциях обмена данными с файлом
/bin/prog1 .exe. При неудачной попытке открытия файла (нет прав для выполнения
затребованной операции, неверное имя файла) переменной fd присваивается
значение -1, которое является индикатором ошибки для всех системных вызовов
UNIX. в начало
63.
Организация
контроля доступа к файлам.
Доступ к файлам как частный
случай доступа к разделяемым ресурсам
Файлы
— это частный, хотя и самый популярный, вид разделяемых ресурсов, доступ к
которым операционная система должна контролировать. Существуют и другие виды
ресурсов, с которыми пользователи работают в режиме совместного использования.
Прежде всего это различные внешние устройства: принтеры, модемы,
графопостроители и т. п. Область памяти, используемая для обмена данными между
процессами, также является примером разделяемого ресурса. Да и сами процессы в
некоторых случаях выступают в этой роли, например, когда пользователи ОС посылают
процессам сигналы, на которые процесс должен реагировать.
Во
всех этих случаях действует общая схема: пользователи пытаются выполнить с
разделяемым ресурсом определенные операции, а ОС должна решать, имеют ли
пользователи на это право. Пользователь осуществляет доступ к объектам
операционной системы не непосредственно, а с помощью прикладных процессов, которые
запускаются от его имени. Для каждого типа объектов существует набор операций,
которые с ними можно выполнять. Система контроля доступа ОС должна
предоставлять средства для задания прав пользователей по отношению к объектам
дифференцированно по операциям.
Во
многих операционных системах реализованы механизмы, которые позволяют управлять
доступом к объектам различного типа с единых позиций. Так, представление
устройств ввода-вывода в виде специальных файлов в операционных системах UNIX
является примером такого подхода: в этом случае при доступе к устройствам
используются те же атрибуты безопасности и алгоритмы, что и при доступе к
обычным файлам и каталогам. Еще дальше продвинулась в этом направлении
операционная система Windows NT. В ней используется унифицированная структура —
объект безопасности, — которая создается не только для файлов и внешних
устройств, но и для любых разделяемых ресурсов: секций памяти, синхронизирующих
примитивов типа семафоров и мьютексов и т. п. Это позволяет использовать в
Windows NT для контроля доступа к ресурсам любого вида общий модуль ядра —
менеджер безопасности.
В
качестве субъектов доступа могут выступать как отдельные пользователи, так и
группы пользователей. Определение индивидуальных прав доступа для каждого
пользователя позволяет максимально гибко задать политику расходования
разделяемых ресурсов в вычислительной системе. Однако этот способ приводит в
больших системах к чрезмерной загрузке администратора рутинной работой по
повторению одних и тех же операций для пользователей с одинаковыми правами.
Объединение таких пользователей в группу и задание прав доступа в целом для
группы является одним из основных приемов администрирования в больших системах.
У
каждого объекта доступа существует владелец. Владельцем может быть как
отдельный-' пользователь, так и группа пользователей. Во многих операционных
системах существует особый пользователь (superuser, root, administrator),
который имеет все права по отношению к любым объектам системы, не обязательно
являясь их владельцем. Под таким именем работает администратор системы,
которому необходим полный доступ ко всем файлам и устройствам для управления
политикой доступа.
Различают
два основных подхода к определению прав доступа.
ñ Избирательный доступ имеет
место, когда для каждого объекта сам владелец может определить допустимые
операции с объектами. Этот подход называется также произвольным
(отdiscretionary — предоставленный на собственное усмотрение) доступом,
так как позволяет администратору и владельцам объектов определить права доступа
произвольным образом, по их желанию. Между пользователями и группами
пользователей в системах с избирательным доступом нет жестких иерархических
взаимоотношений, то есть взаимоотношений, которые определены по умолчанию и
которые нельзя изменить. Исключение делается только для администратора, по
умолчанию наделяемого всеми правами.
ñ Мандатный доступ
(от mandatory — обязательный, принудительный) — это такой подход к
определению прав доступа, при котором система наделяет пользователя
определенными правами по отношению к каждому разделяемому ресурсу (в данном
случае файлу) в зависимости от того, к какой группе пользователь отнесен. От
имени системы выступает администратор, а владельцы объектов лишены возможности
управлять доступом к ним по своему усмотрению. Все группыетн пользователей в
такой системе образуют строгую иерархию, причем каждая группа пользуется всеми
правами группы более низкого уровня иерархии, к которым добавляются права
данного уровня. Членам какой-либо группы не разрешается предоставлять свои
права членам групп более низких уровней иерархии. Мандатный способ доступа
близок к схемам, применяемым для доступа к секретным документам: пользователь
может входить в одну из групп, отличающихся правом на доступ к документам с
соответствующим грифом секретности, например «для служебного пользования»,
«секретно», «совершенно секретно» и «государственная тайна». При этом
пользователи группы «совершенно секретно» имеют право работать с документами
«секретно» и «для служебного пользования», так как эти виды доступа разрешены для
более низких в иерархии групп. Однако сами пользователи не распоряжаются
правами доступа — этой возможностью наделен только особый чиновник учреждения.
Мандатные
системы доступа считаются более надежными, но менее гибкими, обычно они
применяются в специализированных вычислительных системах с повышенными
требованиями к защите информации. В универсальных системах используются, как
правило, избирательные методы доступа.
Каждый
пользователь и каждая группа пользователей обычно имеют символьное имя, а также
уникальный числовой идентификатор. При выполнении процедуры логического входа в
систему пользователь сообщает свое символьное имя и пароль, а операционная
система определяет соответствующие числовые идентификаторы пользователя и групп,
в которые он входит. Вся идентификационные данные, в том числе имена и идентификаторы
пользователей и групп, пароли пользователей, а также сведения о вхождении
пользователя в группы хранятся в специальном файле (файл /etc/passwd в UNIX)
или специальной базе данных (в Windows NT).
Вход
пользователя в систему порождает процесс-оболочку, который поддерживает диалог
с пользователем и запускает для него другие процессы. Процесс-оболочка получает
от пользователя символьное имя и пароль и находит по ним числовые
идентификаторы пользователя и его групп. Эти идентификаторы связываются с
каждым процессом, запущенным оболочкой для данного пользователя. Говорят, что
процесс выступает от имени данного пользователя и данных групп пользователей. В
наиболее типичном случае любой порождаемый процесс наследует идентификаторы
пользователя и групп от процесса родителя.
Определить
права доступа к ресурсу — значит определить для каждого пользователя набор
операций, которые ему разрешено применять к данному ресурсу. В разных операционных
системах для одних и тех же типов ресурсов может быть определен свой список
дифференцируемых операций доступа. Для файловых объектов этот список может включать
следующие операции:
ñ создание файла;
ñ уничтожение файла;
ñ открытие файла;
ñ закрытие файла;
ñ чтение файла;
ñ запись в файл;
ñ дополнение файла;
ñ поиск в файле;
ñ получение атрибутов файла;
ñ установка новых значений
атрибутов;
ñ переименование;
ñ выполнение файла;
ñ чтение каталога;
ñ смена владельца;
ñ изменение прав доступа.
Набор
файловых операций ОС может состоять из большого количества элементарных
операций, а может включать всего несколько укрупненных операций. Приведенный
выше список является примером первого подхода, который позволяет весьма тонко
управлять правами доступа пользователей, но создает значительную нагрузку на
администратора. Пример укрупненного подхода демонстрируют операционные системы
семейства UNIX, в которых существуют всего три операции с файлами и каталогами:
читать (read, г), писать (write, w) и выполнить (execute, x). Хотя в UNIX для
операций используется всего три названия, в действительности им соответствует
гораздо больше операций. Например, содержание операции выполнить зависит от
того, к какому объекту она применяется. Если операция выполнить файл интуитивно
понятна, то операция выполнить каталог интерпретируется как поиск в каталоге
определенной записи. Поэтому администратор UNIX, по сути, располагает большим
списком операций, чем это кажется на первый взгляд.
В
ОС Windows NT разработчики применили гибкий подход — они реализовали
возможность работы с операциями над файлами на двух уровнях: по умолчанию
администратор работает на укрупненном уровне (уровень стандартных операций), а
при желании может перейти на элементарный уровень (уровень индивидуальных
операций).
В
самом общем случае права доступа могут быть описаны матрицей прав доступа, в
которой столбцы соответствуют всем файлам системы, строки — всем пользователям,
а на пересечении строк и столбцов указываются разрешенные операции (рис. 7.28).
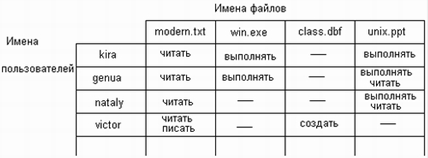
Практически
во всех операционных системах матрица прав доступа хранится «по частям», то
есть для каждого файла или каталога создается так называемый список управления
доступом (Access Control List, ACL), в котором описываются права на выполнение
операций пользователей и групп пользователей по отношению к этому файлу или
каталогу. Список управления доступа является частью характеристик файла или
каталога и хранится на диске в соответствующей области, например в индексном
дескрипторе inode файловой системы ufs. He все файловые системы поддерживают
списки управления доступом, например, его не поддерживает файловая система FAT,
так как она разрабатывалась для однопользовательской однопрограммной операционной
системы MS-DOS, для которой задача защиты от несанкционированного доступа не
актуальна.
Обобщенно
формат списка управления доступом можно представить в виде набора
идентификаторов пользователей и групп пользователей, в котором для каждого
идентификатора указывается набор разрешенных операций над объектом (рис. 7.29).
Говорят, что список ACL состоит из элементов управления доступом (Access
Control Element, АСЕ), при этом каждый элемент соответствует одному
идентификатору. Список ACL с добавленным к нему идентификатором владельца
называют характеристиками безопасности.
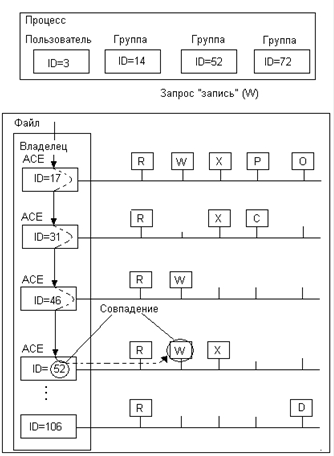
В
приведенном на рисунке примере процесс, который выступает от имени пользователя
с идентификатором 3 и групп с идентификаторами 14, 52 и 72, пытается выполнить
операцию записи (W) в файл. Файлом владеет пользователь с идентификатором 17.
Операционная система, получив запрос на запись, находит характеристики
безопасности файла (на диске или в буферной системной области) и
последовательно сравнивает все идентификаторы процесса с идентификатором
владельца файла и идентификаторами пользователей и групп в элементах АСЕ. В
данном примере один из идентификаторов группы, от имени которой выступает
процесс, а именно 52, совпадает с идентификатором одного из элементов АСЕ. Так
как пользователю с идентификатором 52 разрешена операция чтения (признак W
имеется в наборе операций этого элемента), то ОС разрешает процессу выполнение
операции.
Описанная
обобщенная схема хранения информации о правах доступа и процедуры проверки
имеет в каждой операционной системе свои особенности, которые рассматриваются
далее на примере операционных систем UNIX и Windows NT. в начало
64.
Контроль доступа
к файлам на примере Unix.
В
ОС UNIX права доступа к файлу или каталогу определяются для трех субъектов:
ñ владельца файла
(идентификатор User ID, UID);
ñ членов группы, к которой принадлежит
владелец (Group ID, GID);
ñ всех остальных
пользователей системы.
С
учетом того что в UNIX определены всего три операции над файлами и каталогами
(чтение, запись, выполнение), характеристики безопасности файла включают девять
признаков, задающих возможность выполнения каждой из трех операций для каждого
из трех субъектов доступа.
Здесь
г, w и х обозначают операции чтения, записи и выполнения соответственно.
С
каждым процессом UNIX связаны два идентификатора: пользователя, от имени
которого был создан этот процесс, и группы, к которой принадлежит данный
пользователь. Эти идентификаторы носят название реальных идентификаторов
пользователя: Real User ID, RUID и реальных идентификаторов группы: Real Group
ID, RGID. Однако при проверке прав доступа к файлу используются не эти
идентификаторы, а так называемые эффективные идентификаторы пользователя:
Effective User ID, EUID и эффективные идентификаторы группы: Effective Group
ID, EGID.
Введение
эффективных идентификаторов позволяет процессу выступать в некоторых случаях от
имени пользователя и группы, отличных от тех, которые ему достались при
рождении. В исходном состоянии эффективные идентификаторы совпадают с
реальными.
Случаи,
когда процесс выполняет системный вызов ехес запуска приложения,
хранящегося в некотором файле, в UNIX связаны со сменой процессом исполняемого
кода. В рамках данного процесса начинает выполняться новый код, и если в
характеристиках безопасности этого файла указаны признаки разрешения смены
идентификаторов пользователя и группы, то происходит смена эффективных
идентификаторов процесса. Файл имеет два признака разрешения смены
идентификатора — Set User ID on execution (SUID) и Set Group ID on execution
(SGID), которые разрешают смену идентификаторов пользователя и группы при выполнении
данного файла.
Механизм
эффективных идентификаторов позволяет пользователю получать некоторые виды
доступа, которые ему явно не разрешены, но только с помощью вполне
ограниченного набора приложений, хранящихся в файлах с установленными
признаками смены идентификаторов. Пример такой ситуации приведен на рис. 7.31.
Первоначально
процесс А имел эффективные идентификаторы пользователя и группы (12 и 23
соответственно), совпадающие с реальными. На каком-то этапе работы процесс
запросил выполнение приложения из файла b.ехе. Процесс может выполнить файл
b.ехе, хотя его эффективные идентификаторы не совпадают с идентификатором
владельца и группы файла, так как выполнение разрешено всем пользователям.В ОС
UNIX права доступа к файлу или каталогу определяются для трех субъектов:
ñ
владельца
файла (идентификатор User ID, UID);
ñ
членов
группы, к которой принадлежит владелец (Group ID, GID);
ñ
всех
остальных пользователей системы.
Использование
модели файла как универсальной модели разделяемого ресурса позволяет в UNIX
применять одни и те же механизмы для контроля доступа к файлам, каталогам,
принтерам, терминалам и разделяемым сегментам памяти.
Система
управления доступом ОС UNIX была разработана в 70-е годы и с тех пор мало
изменилась. Эта достаточно простая система позволяет во многих случаях решить
поставленные перед администратором задачи по предотвращению
несанкционированного доступа, однако такое решение иногда требует слишком
больших ухищрений или же вовсе не может быть реализовано. в начало
65.
Отказоустойчивость
файловых систем.
Диски
и файловые системы, используемые для упорядоченного хранения данных на дисках,
часто представляют собой последний «островок стабильности», на котором находит
спасение пользователь после неожиданного краха системы, разрушившего результаты
его труда, полученные за последние нескольких минут или даже часов, но не сохраненные
на диске. Однако те данные, которые пользователь записывал в течение своего
сеанса работы на диск, останутся, скорее всего, нетронутыми. Вероятность того,
что система при сбое питания или программной ошибке в коде какого-либо
системного модуля будет делать осмысленные действия по уничтожению файлов на
диске, пренебрежимо мала. Поэтому при перезапуске операционной системы после краха
большинство данных, хранящихся в файлах на диске, по-прежнему корректны и
доступны пользователю. Коды и данные операционной системы также хранятся в
файлах, что и позволяет легко ее перезапустить после сбоя, не связанного с
отказом диска или повреждением системных файлов.
Тем
не менее диски также могут отказывать, например, по причине нарушения магнитных
свойств отдельных областей поверхности. В данном разделе рассматриваются
методы, которые повышают устойчивость вычислительной системы к отказам дисков
за счет использования избыточных дисков и специальных алгоритмов управления
массивами таких дисков.
Другой
причиной недоступности данных после сбоя системы может служить нарушение
целостности служебной информации файловой системы, произошедшее из-за
незавершенности операций по изменению этой информации при крахе системы.
Примером такого нарушения может служить несоответствие между адресной
информацией файла, хранящейся в каталоге, и фактическим размещением кластеров
файла. Для борьбы с этим явлением применяются так называемые восстанавливаемые
файловые системы, которые обладают определенной степенью устойчивости к сбоям и
отказам компьютера (при сохранении работоспособности диска, на котором
расположена данная файловая система). Комплексное применение отказоустойчивых
дисковых массивов и восстанавливаемых файловых систем существенно повышают
такой важный показатель вычислительной системы, как общая надежность.
Восстанавливаемость
файловых систем
Восстанавливаемость
файловой системы — это свойство, которое гарантирует, что в случае отказа
питания или краха системы, когда все данные в оперативной памяти безвозвратно
теряются, все начатые файловые операции будут либо успешно завершены, либо
отменены безо всяких отрицательных последствий для работоспособности файловой
системы.
Любая
операция над файлом (создание, удаление, запись, чтение и т. д.) может быть
представлена в виде некоторой последовательности подопераций. Последствия сбоя
питания или краха ОС зависят от того, какая операция ввода-вывода выполнялась в
этот момент, в каком порядке выполнялись подоперации и до какой подоперации
продвинулось выполнение операции к этому моменту.
Некорректность
файловой системы может возникать не только в результате насильственного
прерывания операций ввода-вывода, выполняемых непосредственно с диском, но и в
результате нарушения работы дискового кэша. Кэширование данных с диска
предполагает, что в течение некоторого времени результаты операций ввода-вывода
никак не сказываются на содержимом диска — все изменения происходят с копиями
блоков диска, временно хранящихся в буферах оперативной памяти. В этих буферах
оседают данные из пользовательских файлов и служебная информация файловой
системы, такая как каталоги, индексные дескрипторы, списки свободных, занятых и
поврежденных блоков и т. п.
Для
согласования содержимого кэша и диска время от времени выполняется запись всех
модифицированных блоков, находящихся в кэше, на диск. Выталкивание блоков на
диск может выполняться либо по инициативе менеджера дискового кэша, либо по
инициативе приложения. Менеджер дискового кэша вытесняет блоки из кэша в
следующих случаях:
ñ если необходимо освободить
место в кэше для новых данных;
ñ если к менеджеру поступил
запрос от какого-либо приложения или модуля ОС на запись указанных в запросе
блоков на диск;
ñ при выполнении регулярного,
периодического сброса всех модифицированных блоков кэша на диск (как это
происходит, например, в результате работы системного вызова sync в ОС UNIX).
Кроме
того, в распоряжение приложений обычно предоставляются средства, с помощью которых
они могут запросить у подсистемы ввода-вывода операцию сквозной записи; при ее
выполнении данные немедленно и практически одновременно записываются и на диск,
и в кэш.
Несмотря
на то что период полного сброса кэша на диск обычно выбирается весьма коротким
(порядка 10-30 секунд), все равно остается высокая вероятность того, что при
возникновении сбоя содержимое диска не в полной мере будет соответствовать
действительному состоянию файловой системы — копии некоторых блоков с
обновленным содержимым система может не успеть переписать на диск. Для
восстановления некорректных файловых систем, использующих кэширование диска, в
операционных системах предусматриваются специальные утилиты, такие как fsck для
файловых систем s5/uf, ScanDisk для FAT или Chkdsk для файловой системы HPFS.
Однако объем несоответствий может быть настолько большим, что восстановление
файловой системы после сбоя с помощью стандартных системных средств становится
невозможным.
Протоколирование транзакций
Проблемы,
связанные с восстановлением файловой системы, могут быть решены при помощи
техники протоколирования транзакций, которая сводится к следующему. В системе
должны быть определены транзакции (transactions) — неделимые работы, которые не
могут быть выполнены частично. Они либо выполняются полностью, либо вообще не
выполняются.
Модель
неделимой транзакции пришла из бизнеса. Пусть, например, идет переговорный
процесс двух фирм о покупке-продаже некоторого товара. В процессе переговоров
условия договора могут многократно меняться, уточняться. Пока договор еще не
подписан обеими сторонами, каждая из них может от него отказаться. Но после
подписания контракта сделка (транзакция) должна быть выполнена от начала и до
конца. Если же контракт не подписан, то любые действия, которые были уже проделаны,
отменяются или объявляются недействительными. В файловых системах такими транзакциями
являются операции ввода-вывода, изменяющие содержимое файлов, каталогов или
других системных структур файловой системы (например, индексных дескрипторов
ufs или элементов FAT). Пусть к файловой системе поступает запрос на выполнение
той или иной операции ввода-вывода. Эта операция включает несколько шагов,
связанных с созданием, уничтожением и модификацией объектов файловой системы.
Если все подоперации были благополучно завершены, то транзакция считается
выполненной. Это действие называется фиксацией (committing) транзакции. Если же
одна или более подопераций не успели выполниться из-за сбоя питания или краха
ОС, тогда для обеспечения целостности файловой системы все измененные в рамках
транзакции данные файловой системы должны быть возвращены точно в то состояние,
в котором они находились до начала выполнения транзакции. Так, например,
транзакцией может быть представлена операция удаления файла. Действительно, для
целостности файловой системы необходимо, чтобы все требуемые при выполнении
данной операции изменения каталога и таблицы распределения дисковой памяти были
сделаны в полном объеме. Либо, если во время операции произошел сбой, каталог и
таблица распределения памяти должны быть приведены в исходное состояние.
С
другой стороны, в файловой системе существуют операции, которые не изменяют
состояния файловой системы и которые вследствие этого нет необходимости
рассматривать как транзакции. Примерами таких операций являются чтение файла,
поиск файла на диске, просмотр атрибутов файла.
Незавершенная
операция с диском несет угрозу целостности файловой системы. Каким же образом
файловая система может реализовать свойство транзакций «все или ничего»?
Очевидно, что решение в этом случае может быть одно — необходимо
протоколировать (запоминать) все изменения, происходящие в рамках транзакции,
чтобы на основе этой информации в случае прерывания транзакции можно было
отменить все уже выполненные подоперации, то есть сделать так называемый откат
транзакции.
В
файловых системах с кэшированием диска для восстановления системы после сбоя
кроме отката незавершенных транзакций необходимо выполнить дополнительное
действие — повторение зафиксированных транзакций. Когда происходит сбой по
питанию или крах ОС, все данные, находящиеся в оперативной памяти, теряются, в
том числе и модифицированные блоки данных, которые менеджер дискового кэша не
успел вытолкнуть на диск. Единственный способ восстановить утерянные изменения
данных — это повторить все завершенные транзакции, которые участвовали в
модификации этих блоков. Чтобы обеспечить возможность повторения транзакций,
система должна включать в протокол не только данные, которые могут быть использованы
для отката транзакции, но и данные, которые позволят в случае необходимости
повторить всю транзакцию.
Для
восстановления файловой системы используется упреждающее протоколирование
транзакций. Оно заключается в том, что перед изменением какого-либо блока
данных на диске или в дисковом кэше производится запись в специальный системный
файл — журнал транзакций (log file), где отмечается, какая транзакция делает
изменения, какой файл и блок изменяются и каковы старое и новое значения
изменяемого блока. Только после успешной регистрации всех подопераций в журнале
делаются изменения в исходных блоках. Если транзакция прерывается, то
информация журнала регистрации используется для приведения файлов, каталогов и
служебных данных файловой системы в исходное состояние, то есть производится
откат. Если транзакция фиксируется, то и об этом делается запись в журнал регистрации,
но новые значения измененных данных сохраняются в журнале еще некоторое время,
чтобы сделать возможным повторение транзакции, если это потребуется. в начало
66.
Процедура
самовосстановления NTFS.
Файловая
система NTFS является восстанавливаемой файловой системой, однако
восстанавливаемость обеспечивается только для системной информации файловой
системы, то есть каталогов, атрибутов безопасности, битовой карты занятости
кластеров и других системных файлов. Сохранность данных пользовательских файлов,
работа с которыми выполнялась в момент сбоя, в общем случае не гарантируется.
Для
повышения производительности файловая система NTFS использует дисковый кэш, то
есть все изменения файлов, каталогов и управляющей информации выполняются
сначала над копиями соответствующих блоков в буферах оперативной памяти и
только спустя некоторое время переносятся на диск. Однако кэширование, как уже
было сказано, повышает риск разрушения файловой системы. В таких условиях NTFS
обеспечивает отказоустойчивость с помощью технологии протоколирования
транзакций и восстановления системных данных. Пользовательские данные, которые
в момент краха находились в дисковом кэше и не успели записаться на диск, в
NTFS не восстанавливаются.
Журнал
регистрации транзакций в NTFS делится на две части: область рестарта и область
протоколирования.
ñ Область рестарта содержит
информацию о том, с какого места необходимо будет начать читать журнал
транзакций для проведения процедуры восстановления системы после сбоя или краха
ОС. Эта информация представляет собой указатель на определенную запись в
области протоколирования. Для надежности в файле журнала регистрации хранятся
две копии области рестарта.
ñ Область протоколирования содержит
записи обо всех изменениях в системных данных файловой системы, произошедших в
результате выполнения транзакций в течение некоторого, достаточно большого
периода. Все записи идентифицируются логическим последовательным номером LSN (Logical
Sequence Number). Записи о подоперациях, принадлежащих одной транзакции,
образуют связанный список: каждая последующая запись содержит номер предыдущей
записи. Заполнение области протоколирования идет циклически: после исчерпания
всей памяти, отведенной под область протоколирования, новые записи помещаются
на место самых старых.
Существует
несколько типов записей в журнале транзакций: запись модификации, запись
контрольной точки, запись фиксации транзакции, запись таблицы модификации,
запись таблицы модифицированных страниц.
Запись
модификации заносится в журнал транзакций относительно каждой подоперации,
которая модифицирует системные данные файловой системы. Эта запись состоит из
двух частей: одна содержит информацию, необходимую системе для повторения этого
действия, а другая — информацию для его отмены. Информация о модификации хранится
в двух формах — в физическом и в логическом описаниях. Логическое описание используется
программным обеспечением уровня приложений и формулируется в терминах операций,
например «выделить файловую запись в MFT» или «удалить имя из корневого
индекса». На нижнем уровне программного обеспечения, к которому относятся
модули самой NTFS, используется менее компактное, но более простое физическое
описание, сводящееся к указанию диапазона байт на диске, в которые необходимо
поместить определенные значения.
Журнал
транзакций, как и все остальные файлы, кэшируется в буферах оперативной памяти
и периодически сбрасывается на диск.
Файловая
система NTFS все действия с журналом транзакций выполняет только путем запросов
к специальной службе LFS (Log File Service). Эта служба размещает в журнале
новые записи, сбрасывает на диск все записи до некоторого заданного номера,
считывает записи в прямом и обратном порядке и выполняет некоторые другие
действия над записями журнала.
Прежде
чем выполнить любую транзакцию, NTFS вызывает службу журнала транзакций LFS для
регистрации всех подопераций в журнале транзакций. И только после этого
описанные подоперации действительно выполняются над копиями блоков данных
файловой системы, находящимися в кэше. Когда все подоперации транзакции
выполнены, с помощью службы LFS транзакция фиксируется. Это выражается в том,
что в журнал заносится специальный вид записи — запись фиксации транзакции.
Параллельно
с регистрацией и выполнением транзакций происходит процесс выталкивания блоков
кэша на диск. Сброс на диск измененных блоков выполняется в два этапа: сначала
сбрасываются блоки журнала, а потом — модифицированные блоки транзакций. Такой
порядок реализуется следующим образом. Каждый раз, когда диспетчер кэша
принимает решение о том, что определенные модифицированные блоки (не
обязательно все) должны быть вытеснены на диск, он сообщает об этом службе LFS.
В ответ на это сообщение LFS обращается к диспетчеру кэша с запросом о записи
на диск всех измененных блоков журнала. После того как блоки журнала сброшены
на диск, сбрасываются на диск модифицированные блоки транзакций, среди которых
могут быть, конечно, и блоки системных данных файловой системы.
Такая
двухэтапная процедура сброса данных кэша на диск делает возможным
восстановление файловой системы, если во время записи модифицированных блоков
из кэша на диск произойдет сбой. Действительно, какие бы неприятности не
произошли во время записи модифицированных блоков на диск, вся информация об
изменениях, произведенных в этих блоках, уже записана на диск в файл журнала
транзакций. Заметим, что все действия, которые были выполнены файловой системой
в интервале между последним сбросом данных на диск и сбоем, отменяются сами
собой, поскольку все они проводятся только над блоками в кэше и не вызывают
никаких изменений содержимого диска.
Какие
же дефекты может иметь файловая система после сбоя?
Во-первых,
это несогласованность системных данных, возникшая в результате незавершенности
транзакций, которые были начаты еще до момента последнего сброса данных из кэша
на диск. Чтобы устранить несогласованность, вызванную этой причиной, требуется
сделать откат для всех транзакций, незафиксированных к моменту последнего
сброса кэша. Для примера, изображенного на рисунке, такими транзакциями
являются транзакции А и С. В каждый момент времени NTFS располагает списком
незафиксированных транзакций, называемым таблицей незавершенных транзакций
(transaction table). Для каждой незавершенной транзакции эта таблица содержит
последовательный номер LSN последней по времени подоперации, выполненной в рамках
данной транзакции. По этому номеру может быть найдена вся цепочка подопераций
транзакции.
Во-вторых,
противоречия в файловой системе могут быть вызваны потерей тех изменений,
которые были сделаны транзакциями, завершившимися еще до сброса кэша, но
которые не были записаны на диск в ходе последнего сброса. На рисунке такой
транзакцией может оказаться транзакция В. Чтобы определить, какие завершенные
транзакции надо повторять, система ведет таблицу модифицированных
страниц {dirty page table), находящихся в данный момент в кэше. В таблице
для каждой модифицированной страницы указывается, какая транзакция вызвала эти
изменения. Повторение транзакций, которые имели дело со страницами, указанными
в данном списке, гарантирует, что ни одно изменение не будет потеряно.
Таблицы
модифицированных страниц и незавершенных транзакций создаются NTFS на основании
записей журнала транзакций и поддерживаются в оперативной памяти. Следует
подчеркнуть, что обе эти таблицы не добавляют новой информации в журнал
транзакций, они лишь представляют информацию, содержащуюся в записях журнала, в
концентрированном виде, более удобном для использования при восстановлении. Содержимое
таблиц фиксируется в журнале транзакций во время выполнения операции
контрольная точка.
Операция
контрольная точка выполняется каждые 5 секунд и включает выполнение следующих
действий. Сначала в области протоколирования журнала транзакций создаются две
записи — запись таблицы незавершенных транзакций и запись таблицы
модифицированных страниц, содержащие копии соответствующих таблиц. Затем номера
этих записей включаются в запись контрольной точки, которая также создается в
области протоколирования журнала транзакций. Сделав запись контрольной точки,
NTFS помещает ее номер LSN в область рестарта.
Заметим,
что процессы создания контрольных точек и сброса блоков данных из кэша на диск
протекают асинхронно. Когда в результате сбоя из оперативной памяти исчезает
вся информация, в том числе из таблиц незавершенных транзакций и
модифицированных страниц, состояние этих таблиц, хотя и несколько устаревшее,
сохраняется на диске в файле журнала транзакций. Кроме того, здесь же имеется
несколько более поздних записей, которые были сделаны в период между
сохранением таблиц и сбросом кэша. При восстановлении файловая система
обрабатывает эти записи и вносит изменения в таблицы незавершенных транзакций и
модифицированных страниц, сохраненные в журнале.
Процесс
восстановления файловой системы включает следующие шаги:
1.
Чтение области рестарта из файла журнала транзакций и определение номера самой
последней по времени записи о контрольной точке.
2.
Чтение записи контрольной точки и определение номеров записей таблицы незавершенных
транзакций и таблицы модифицированных страниц.
3.
Чтение и корректировка таблиц незавершенных транзакций и модифицированных
страниц на основании записей, сделанных в журнале транзакций уже после
сохранения таблиц в журнале, но еще до записи журнала на диск.
4.
Анализ таблицы модифицированных страниц, определение номера самой ранней записи
модификации страницы.
5.
Чтение журнала транзакций в прямом направлении, начиная с самой ранней записи
модификации, найденной при анализе таблицы модифицированных страниц. При этом
система выполняет повторение завершенных транзакций, в результате которого
устраняются все несоответствия файловой системы, вызванные потерями
модифицированных страниц в кэше во время сбоя или краха операционной системы.
6.
Анализ таблицы незавершенных транзакций, определение номера самой поздней
подоперации, выполненной в рамках незавершенной транзакции.
7.
Чтение журнала транзакций в обратном направлении. Учитывая, что все подоперации
каждой транзакции связаны в список, система легко переходит от одной записи
модификации к другой, извлекает из них информацию, необходимую для отмены, и
выполняет откат незавершенных транзакций.
Операция
отмены сама является транзакцией, поскольку связана с модификацией системных
блоков файловой системы — поэтому она протоколируется обычным образом в журнале
транзакций. По отношению к ней также могут быть применены операции повторения
или отката. в
начало
67.
Избыточные
дисковые подсистемы RAID.
В основе средств обеспечения отказоустойчивости дисковой памяти лежит общий для всех отказоустойчивых систем принцип избыточности, и дисковые подсистемы RAID (Redundant Array of Inexpensive Disks, дословно — «избыточный массив недорогих дисков») являются примером реализации этого принципа. Идея технологии RAID-массивов состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. Существуют также различные модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
· степень избыточности хранимой информации;
· производительность операций чтения и записи;
· степень отказоустойчивости.
В логическом устройстве RAID-0 общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0 могут отличаться размерами блоков данных.
По сравнению с одиночным диском, в котором данные записываются и считываются с диска последовательно, производительность дисковой конфигурации RAID-0 значительно выше за счет одновременности операций записи/чтения по всем дискам массива.
Уровень RAID-0 не обладает избыточностью данных, а значит, не имеет возможности повысить отказоустойчивость. Если при считывании произойдет сбой, то данные будут безвозвратно испорчены. Более того, отказоустойчивость даже снижается, поскольку если один из дисков выйдет из строя, то восстанавливать придется все диски массива. Имеется еще один недостаток — если при работе с RAID-0 объем памяти логического устройства потребуется изменить, то сделать это путем простого добавления еще одного диска к уже имеющимся в RAID-массиве дискам невозможно без полного перераспределения информации по всему изменившемуся набору дисков.
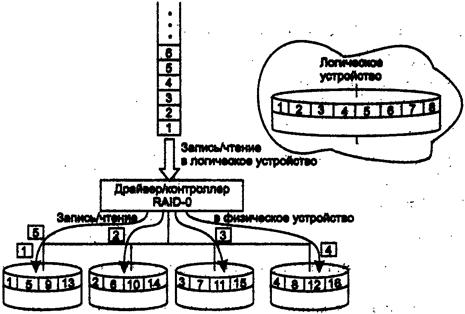
Рисунок 31. Организация массива RAID-0
Уровень RAID-1 реализует подход, называемый зеркальным копированием. Логическое
устройство в этом случае образуется на основе одной или нескольких пар дисков,
в которых один диск является основным, а другой диск (зеркальный) дублирует
информацию, находящуюся на основном диске. Если основной диск выходит из строя,
зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная
отказоустойчивость логического устройства. Все данные хранятся на логическом
устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется
лишь на 50%.
При внесении изменений в данные,
расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива
дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом
дублирование операций абсолютно прозрачно для пользователя и приложений.
Удвоение количества операций записи снижает, хотя и не очень значительно,
производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием
дисков дублируются и их контроллеры. Такое дублирование помимо повышения
скорости операций записи, обеспечивает большую надежность системы — данные на
зеркальном диске останутся доступными не только при сбое диска, но и в случае
сбоя дискового контроллера.
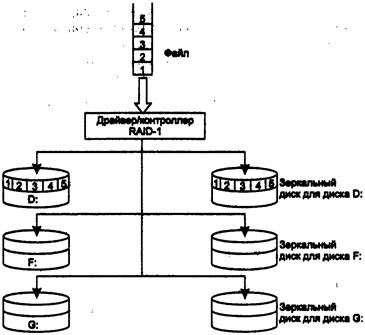
Рисунок 32. Организация массива RAID-1
Уровень RAID-2 расщепляет данные побитно: первый бит записывается на первый
диск, второй бит — на второй диск й т. д. Отказоустойчивость реализуется в
RAID-2 путем использования для кодирования данных корректирующего кода
Хэмминга, который обеспечивает исправление однократных ошибок и обнаружение
двукратных ошибок. Избыточность обеспечивается за счет нескольких дополнительных
дисков, куда записывается код коррекции ошибок. Так, массив с числом основных
дисков от 16 до 32 должен иметь три дополнительных диска для хранения кода
коррекции. RAID-2 обеспечивает высокую производительность и надежность, но он
применяется в основном в мэйнфреймах и суперкомпьютерах. В сетевых файловых
серверах этот метод в настоящее время практически не используется из-за высокой
стоимости его реализации.
В массивах RAID-3 используется расщепление данных на массиве дисков с выделением одного диска на весь набор для контроля четности. То есть если имеется массив из N дисков, то запись на N-1 из них производится параллельно с побайтным расщеплением, а N-й диск используется для записи контрольной информации о четности. Диск четности является резервным. Если какой-либо диск выходит из строя, то Данные остальных дисков плюс данные о четности резервного диска позволяют не только определить, какой из дисководов массива вышел из строя, но и восстановить утраченную информацию. Это восстановление может выполняться динамически, по мере поступления запросов, или в результате выполнения специальной процедуры восстановления, когда содержимое отказавшего диска заново генерируется и записывается на резервный диск.
Минимальное количество дисков, необходимое для создания конфигурации RAID-3, равно трем. В этом случае избыточность достигает максимального значения — 33 %. При увеличении числа дисков степень избыточности снижается, так, для 33 дисков она составляет менее 1 %.
Уровень RAID-3 позволяет выполнять одновременное чтение или запись данных на несколько дисков для файлов с длинными записями, однако следует подчеркнуть, что в каждый момент выполняется только один запрос на ввод-вывод, то есть RAID-3 позволяет распараллеливать ввод-вывод в рамках только одного процесса. Таким образом, уровень RAID-3 повышает как надежность, так и скорость обмена информацией.
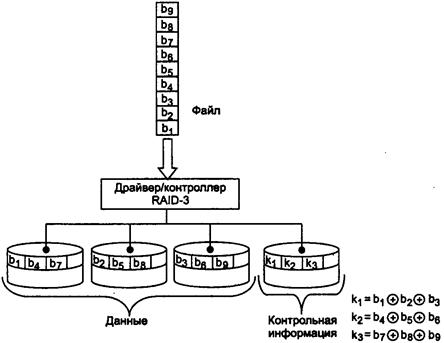
Рисунок 33.Организация массивов RAID-3
Организация RAID-4 аналогична RAID-3, за тем исключением, что данные рас-пределяются на дисках не побайтно, а блоками. За счет этого может происходить независимый обмен с каждым диском. Для хранения контрольной информации также используется один дополнительный диск. Эта реализация удобна для файлов с очень короткими записями и большей частотой операций чтения по сравнению с операциями записи, поскольку в этом случае при подходящем размере блоков диска возможно одновременное выполнение нескольких операций чтения.
В уровне RAID-5 используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по всем дискам массива. При выполнении операции записи требуется в три раза больше оперативной памяти. Каждая команда записи инициирует ту же последовательность «считывание—модификация—запись» в нескольких дисках, как и в методе RAID-4. Наибольший выигрыш в производительности достигается при операциях чтения. Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, скорость записи по сравнению с уровнем RAID-4 увеличивается, однако она все еще гораздо ниже скорости отдельного диска метода RAID-1 или RAID-3.
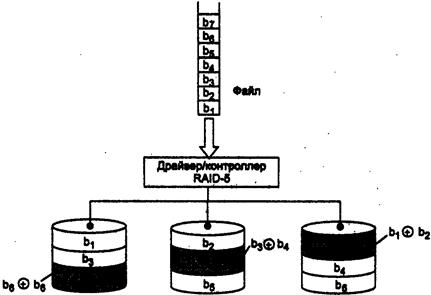
Рисунок 34. Организация массива RAID-5
Кроме рассмотренных выше имеются еще и другие варианты организации совместной
работы избыточного набора дисков, среди них можно особо отметит» технологию
RAID-10, которая представляет собой комбинированный способ, при котором данные «расщепляются» (RAID-0)
и зеркально копируются (RAID-1) без вычисления контрольных сумм.
|
Конфигурация RAID |
Избыточность |
Отказоустойчивость |
Скорость чтения |
Скорость записи |
|
RAID-0 |
Нет |
Нет |
Повышенная |
Повышенная |
|
RAID-1 |
50% |
Есть |
Повышенная |
Пониженная
(в варианте без дуплексирования) |
|
RAID-3,4,5 |
До
33% |
Есть |
Повышенная |
Пониженная
(в разной степени) |
|
RAID-10 |
50% |
Есть |
Повышенная |
Повышенная |
Таблица 2. Характеристики уровней RAID в начало
68.
Многоуровневые
драйверы.
Первоначально термин «драйвер»
применялся в достаточно узком смысле: под драйвером понимался программный
модуль, который:
·
входит в состав ядра операционной системы,
работая в привилегированном режиме;
·
непосредственно управляет внешним устройством,
взаимодействуя с его контроллером с помощью команд ввода-вывода компьютера;
·
обрабатывает прерывания от контроллера
устройства;
·
предоставляет прикладному программисту удобный
логический интерфейс работы с устройством, экранируя от него низкоуровневые
детали управления устройством и организации его данных;
·
взаимодействует с другими модулями ядра ОС с
помощью строго оговоренного интерфейса, описывающего формат передаваемых
данных, структуру буферов, способы включения драйвера
в состав ОС, способы вызова драйвера, набор общих процедур подсистемы
ввода-вывода, которыми драйвер может пользоваться, и т. п.
Постепенно, по мере развития операционных систем и усложнения структуры подсистемы ввода-вывода, наряду с традиционными драйверами в операционных системах появились так называемые высокоуровневые драйверы, которые располагаются в общей модели подсистемы ввода-вывода над традиционными драйверами. Появление высокоуровневых драйверов можно считать дальнейшим развитием идеи многослойной организации подсистемы ввода-вывода. Вместо того чтобы концентрировать все функции по управлению устройством в одном программном модуле, во многих случаях гораздо эффективней распределить их между несколькими модулями в соседних слоях иерархии. Традиционные драйверы, которые стали называть аппаратными драйверами, низкоуровневыми драйверами, или драйверами устройств, подчеркивая их непосредственную связь с управляемым устройствами, освобождаются от высокоуровневых функций и занимаются только низкоуровневыми операциями. Эти низкоуровневые операции составляют фундамент, на котором можно построить тот или иной набор операций в драйверах более высоких уровней.
Несколько драйверов, управляющих одним устройством, но на разных уровнях, можно рассматривать как набор отдельных драйверов или как один многоуровневый драйвер.
Высокоуровневые драйверы оформляются по тем же правилам и придерживаются тех же внутренних интерфейсов, что и аппаратные драйверы. Единственным отличием является то, что высокоуровневые драйверы, как правило, не вызываются по прерываниям, так как взаимодействуют с управляемым устройством через посредничество аппаратных драйверов. Менеджер ввода-вывода управляет драйверами однотипно, независимо от того, к какому уровню он относится. При наличии большого количества драйверов разного уровня усложняются связи между ними, что, в свою очередь, усложняет их взаимодействие, и именно эта ситуация привела к стандартизации внутреннего интерфейса в подсистеме ввода-вывода и выделения специальной оболочки в виде менеджера ввода-вывода, выполняющего служебные функции по организации работы драйверов.
Например, в подсистеме управления графическими устройствами, такими как графические мониторы и принтеры, также существует несколько уровней драйверов. На нижнем уровне работают аппаратные драйверы, которые позволяют управлять конкретным графическим адаптером или принтером определенного типа, заставляя их выполнять некоторый набор примитивных графических операций: вывод точки, окружности, заполнение области цветом, вывод символов и т.п. Высокоуровневые графические драйверы строят на базе этих операций более мощные операции, например масштабирование изображения, преобразование графического формата в соответствии с разрешающими возможностями устройства и т.п. Самый верхний уровень подсистемы составляет менеджер окон, который создает для каждого приложения виртуальный образ экрана в виде набора окон, в которые приложение может выводить свои графические данные. Менеджер управляет окнами, отображая их в определенную область физического экрана или делая их невидимыми, а также предоставляет к ним совместный доступ с контролем прав доступа. Менеджер окон уже не зависит от особенностей конкретного графического устройства, предоставляя высокоуровневым драйверам заниматься преобразованием форматов выводимых данных. в начало
69.
Дисковый кэш.
Во многих операционных системах запросы к блок-ориентированным внешним устройствам с прямым доступом (например, диски) перехватываются промежуточным программным слоем — подсистемой буферизации, называемой также дисковым кэшем. Дисковый кэш располагается между слоем драйверов файловых систем и блок-ориентированными драйверами. При поступлении запроса на чтение некоторого блока диспетчер дискового кэша просматривает свой буферный пул, находящийся в системной области оперативной памяти, и если требуемый блок имеется в кэше, то диспетчер копирует его в буфер запрашивающего, процесса. Операция ввода-вывода считается выполненной, хотя физического обмена с устройством не происходило, при этом выигрыш во времени доступа к файлу очевиден.
При записи данные также попадают сначала в буфер, и только потом, при необходимости освободить место в буферном пуле или же по требованию приложения они действительно переписываются на диск. Операция же записи считается завершенной по завершении обмена с кэшем, а не с диском. Данные блоков диска за время пребывания в кэше могут быть многократно прочитаны прикладными процессами и модулями ОС без выполнения операций ввода-вывода с диском, что также существенно повышает производительность операционной системы.
Дисковый кэш обычно занимает достаточно большую часть оперативной системной памяти, чтобы максимально повысить вероятность попадания в кэш при выполнении дисковых операций. Доля оперативной памяти, отводимой под дисковый кэш, зависит от специфики функций, выполняемых компьютером, — например, сервер приложений выделяет под дисковый кэш меньше памяти, чем файловый сервер, чтобы обеспечить более высокую скорость работы приложений за счет предоставления им большего объема оперативной памяти.
Отрицательным последствием использования дискового кэша является потенциальное снижение надежности системы. При крахе системы, когда по разным причинам теряется информация, находившаяся в оперативной памяти, могут пропасть и данные, которые пользователь считает надежно сохраненными на диске, но которые фактически до диска еще не дошли и хранились в кэше. Обычно для предотвращения таких потерь все содержимое дискового кэша периодически переписывается на диск.
Существуют два способа организации дискового кэша:
Первый способ, который можно назвать традиционным, основан на автономном диспетчере кэша, обслуживающем набор буферов системной памяти и самостоятельно организующим загрузку блока диска в буфер при необходимости, не обращаясь за помощью к другим подсистемам ОС.
Второй способ основан на использовании возможностей подсистемы виртуальной памяти по отображению файлов в память, рассмотренных в предыдущем разделе. При этом способе функции диспетчера дискового кэша значительно сокращаются, так как большую часть работы выполняет подсистема виртуальной памяти, а значит, уменьшается объем ядра ОС и повышается его надежность. Однако применение механизма отображения файлов имеет одно ограничение — во многих файловых системах существуют служебные данные, которые не относятся к файлам, а следовательно, не могут кэшироваться. Поэтому в таких случаях наряду с кэшем на основе виртуальной памяти применяется и традиционный кэш. в начало
70.
Вопросы
безопасности вычислительных систем: свойства безопасной ВС, угрозы безопасности,
средства обеспечения безопасности.
При рассмотрении безопасности
информационных систем обычно выделяют две группы проблем: безопасность
компьютера и сетевая безопасность. К безопасности
компьютера относят все проблемы защиты данных, хранящихся и обрабатывающихся
компьютером, который рассматривается как автономная система. Эти проблемы
решаются средствами операционных систем и приложений, таких как базы данных, а
также встроенными аппаратными средствами компьютера. Под сетевой безопасностью понимают все
вопросы, связанные с взаимодействием устройств в сети, это прежде всего защита
данных в момент их передачи по линиям связи и защита от несанкционированного
удаленного доступа в сеть.
Безопасная информационная система —
это система, которая, во-первых, защищает данные от несанкционированного
доступа, во-вторых, всегда готова предоставить их своим пользователям, а
в-третьих, надежно хранит информацию и гарантирует неизменность данных. Таким
образом, безопасная система по определению
обладает свойствами конфиденциальности, доступности и целостности.
·
Конфиденциальность — гарантия
того, что секретные данные будут доступны только тем пользователям, которым
этот доступ разрешен (такие пользователи называются авторизованными).
·
Доступность — гарантия
того, что авторизованные пользователи всегда получат доступ к данным.
·
Целостность — гарантия
сохранности данными правильных значений, которая обеспечивается запретом для
неавторизованных пользователей каким-либо образом изменять, модифицировать,
разрушать или создавать данные.
Универсальной классификации угроз не существует, возможно, и потому, что нет предела творческим способностям человека, и каждый день применяются новые способы незаконного проникновения в сеть, разрабатываются новые средства мониторинга сетевого трафика, появляются новые вирусы, находятся новые изъяны в существующих программных н аппаратных сетевых продуктах.
Неумышленные угрозы вызываются ошибочными действиями лояльных сотрудников, становятся следствием их низкой квалификации или безответственности. Кроме того, к такому роду угроз относятся последствия ненадежной работы программных и аппаратных средств системы.
Умышленные угрозы могут ограничиваться либо пассивным чтением данных или мониторингом системы, либо включать в себя активные действия, например нарушение целостности и доступности информации, приведение в нерабочее со-стояние приложений и устройств.
Незаконное проникновение может быть реализовано через уязвимые места в системе безопасности с использованием недокументированных возможностей операционной системы. Эти возможности могут позволить злоумышленнику «обойти» стандартную процедуру, контролирующую вход в сеть.
Нелегальные действия легального пользователя — этот тип угроз исходит от легальных пользователей сети, которые, используя свои полномочия, пытаются выполнять действия, выходящие за рамки их должностных обязанностей.
«Подслушивание» внутрисетевого трафика — это незаконный мониторинг сети, захват и анализ сетевых сообщений. Существует много доступных программных и аппаратных анализаторов трафика, которые делают эту задачу достаточно тривиальной.
Построение и поддержка безопасной системы требует системного подхода. В соответствии с этим подходом прежде всего необходимо осознать весь спектр возможных угроз для конкретной сети и для каждой из этих угроз продумать тактику ее отражения. В этой борьбе можно использовать самые разноплановые средства и приемы — морально-этические и законодательные, административные и психологические, защитные возможности программных и аппаратных средств сети.
К морально-этическим средствам
защиты можно отнести всевозможные нормы, которые сложились по мере
распространения вычислительных средств в той или иной стране.
Законодательные средства защиты — это законы, постановления правительства и указы президента, нормативные акты и стандарты, которыми регламентируются правила использования и обработки информации ограниченного доступа, а также вводятся меры ответственности за нарушения этих правил.
Административные меры — это действия, предпринимаемые руководством пред-приятия или организации для обеспечения информационной безопасности.
Психологические меры безопасности могут играть значительную роль в укреплении безопасности системы. Пренебрежение учетом психологических моментов в неформальных процедурах, связанных с безопасностью, может привести к нарушениям защиты.
К физическим средствам защиты относятся экранирование помещений для защиты от излучения, проверка поставляемой аппаратуры на соответствие ее спецификациям и отсутствие аппаратных «жучков», средства наружного наблюдения, устройства, блокирующие физический доступ к отдельным блокам компьютера, различные замки и другое оборудование, защищающие помещения, где находятся носители информации, от незаконного проникновения и т. д. и т. п.
Технические средства
информационной безопасности реализуются программным и аппаратным обеспечением
вычислительных сетей. в
начало
71.
Базовые
технологии безопасности: аутентификация, авторизация, аудит, технология
защищенного канала.
Аутентификация предотвращает доступ к сети
нежелательных лиц и разрешает вход для легальных пользователей. Термин
«аутентификация», в переводе с латинского, означает «установление
подлинности». В процедуре аутентификации
участвуют две стороны: одна сторона доказывает свою аутентичность, предъявляя
некоторые доказательства, а другая сторона — аутентификатор — проверяет эти
доказательства и принимает решение. В качестве доказательства аутентичности
используются самые разнообразные приемы:
· аутентифицируемый может продемонстрировать знание некоего общего для обеих сторон секрета: слова (пароля) или факта (даты и места события, прозвища человека и т. п.);
· аутентифицируемый может продемонстрировать, что он владеет неким уникальным предметом (физическим ключом), в качестве которого может выступать, например, электронная магнитная карта;
· аутентифицируемый может доказать свою идентичность, используя собственные бихарактеристики: рисунок радужной оболочки глаза или отпечатки пальцев, которые предварительно были занесены в базу данных аутентификатора.
Средства авторизации контролируют доступ легальных пользователей к ресурсам системы, предоставляя каждому из них именно те права, которые ему были определены администратором. Система авторизации наделяет пользователя сети правами выполнять определенные действия над определенными ресурсами. Для этого могут быть использованы различные формы предоставления правил доступа, которые часто делят на два класса:
·
избирательный доступ (реализуются в операционных системах
универсального назначения. В наиболее распространенном варианте такого подхода
определенные операции над определенным ресурсом разрешаются или запрещаются
пользователям или группам пользователей, явно указанным своими идентификаторами);
·
мандатный доступ(заключается
в том, что вся ин-формация делится на уровни в зависимости от степени секретности,
а все пользователи сети также делятся на группы).
Аудит — фиксация в
системном журнале событий, связанных с доступом к защищаемым системным ресурсам.
Подсистема аудита современных ОС позволяет дифференцированно задавать перечень
интересующих администратора событий с помощью удобного графического интерфейса.
Средства учета и наблюдения обеспечивают возможность обнаружить и зафиксировать
важные события, связанные с безопасностью, или любые попытки создать, получить
доступ или удалить системные ресурсы. Аудит используется для того, чтобы
засекать даже неудачные попытки «взлома» системы.
Технология защищенного канала призвана обеспечивать безопасность передачи данных по открытой транспортной сети, например по Интернету. Защищенный канал подразумевает выполнение трех основных функций:
· взаимную аутентификацию абонентов при установлении соединения, которая может быть выполнена, например, путем обмена паролями;
· защиту передаваемых по каналу сообщений от несанкционированного доступа, например, путем шифрования;
· подтверждение целостности поступающих по каналу сообщений, например, путем передачи одновременно с сообщением его дайджеста.
Совокупность защищенных каналов, созданных предприятием в публичной сети для объединения своих филиалов, часто называют виртуальной частной. В зависимости от места расположения программного обеспечения защищенного капала различают две схемы его образования:
·
схему с конечными узлами, взаимодействующими через публичную сеть(Рисунок 35, а);
·
схему с оборудованием поставщика услуг публичной сети,
расположенным на границе между частной и публичной сетями(Рисунок 35, б).
Рисунок
35. Два
подхода к образованию защищенного канала в начало
72.
Симметричные
алгоритмы шифрования.
Существует 2 класса криптосистем –
симметричные и асимметричные. В симметричных схемах шифрования (классическая
криптография) секретный ключ шифрования совпадает с секретным ключом дешифрования.
Теоретические основы симметричной криптосистемы изложены Клодом Шенонном в 1949
году.
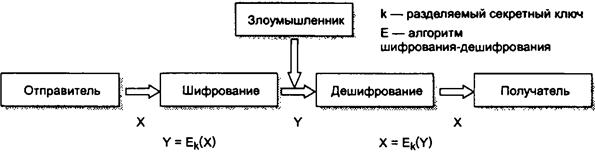
Рисунок 36. Модель симметричного шифрования.
В данной модели 3 участника:
отправитель, получатель, злоумышленник. Задача отправителя заключается в том,
чтобы по открытому каналу передать некоторое сообщение в защищенном виде. Для
этого он зашифровывает открытый текст X ключом k и передает шифрованный текст Y. Задача получателя заключается в том, чтобы
расшифровать Y и
прочитать сообщение X.
Предполагается, что отправитель имеет свой источник ключа. Сгенерированный ключ
заранее по надежному каналу передается получателю. Задача злоумышленника
заключается в перехвате и чтении передаваемых сообщений.
Безопасность,
обеспечиваемая традиционной криптографией, зависит от нескольких факторов:
1.
Криптографический алгоритм должен быть достаточно сильным, чтобы
передаваемое зашифрованное сообщение невозможно было расшифровать без ключа,
используя только различные статистические закономерности зашифрованного
сообщения или какие-либо другие способы его анализа;
2.
Безопасность передаваемого сообщения должна зависеть от секретности
ключа, но не от секретности алгоритма (правило Керкхоффа);
3.
Алгоритм должен быть таким, чтобы нельзя было узнать ключ, даже
зная достаточно много пар (зашифрованное сообщение, незашифрованное сообщение),
полученных при шифровании с использованием данного ключа.
Наиболее популярный стандартный
симметричный алгоритм шифрования данных – DES (Data
Encryption Standard). Алгоритм разработан IBM в 1976 году. Его суть следующая:
Данные шифруются поблочно. Перед
шифрованием любая форма представления данных преобразуются в числовую. Числа
получают путем применения любой открытой процедуры преобразования блока текста
в число. На вход шифрующее функции поступает блок данных , размером 64 бита, он
делится пополам на левую и правую части. На первом этапе на место левой части
результирующего блока помещается правая часть исходного блока. Правая часть
результирующего блока вычисляется как сумма по модулю 2 (XOR) левой и правой частей исходного блока. Затем
на основе случайной двоичной последовательности по определенной схеме
выполняются побитные замены и перестановки. Используемая двоичная
последовательность, представляющая собой ключ данного алгоритма, имеет длину 64
бита, из которых 56 действительно случайны, а 8 предназначены для контроля
ключа.
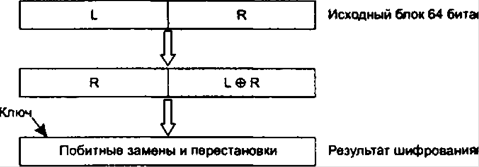
Рисунок 37. Схема шифрования по алгоритму DES
В 2001 году
принят новый стандарт симметричного шифрования, получивший название AES (Advanced Encryption
Standard), основанный на алгоритме Rijndael. AES
обеспечивает
лучшую защиту, т.к. использует 128-разрядные ключи, и более высокую скорость.
В симметричных алгоритмах основную
проблему составляют ключи:
1.
Криптостойкость многих симметричных
алгоритмов зависти от качества ключа;
2.
Принципиальной является проблема передачи
ключа второму участнику шифрования. в начало
73.
Шифрование с
открытым ключом.
Особенность шифрования на основе открытых ключей состоит в том, что одно-временно генерируется уникальная пара ключей, таких, что текст, зашифрованный одним ключом, может быть расшифрован только с использованием второго ключа и наоборот.
В модели криптосхемы с открытым
ключом также три участника: отправитель, получатель, злоумышленник. Задача
отправителя заключается в том, чтобы по открытому каналу связи передать
некоторое сообщение в защищенном виде. Получатель генерирует на своей стороне
два ключа: открытый Е и закрытый D. Закрытый ключ D (часто называемый также
личным ключом) абонент должен сохранять в защищенном месте, а открытый ключ Е
он может передать всем, с кем он хочет поддерживать защищенные отношения.
Открытый ключ используется для шифрования текста, но расшифровать текст можно
только с помощью закрытого ключа. Поэтому открытый ключ передается отправителю
в незащищенном виде. Отправитель, используя открытый ключ получателя, шифрует сообщение
X и передает его получателю. Получатель расшифровывает сообщение своим закрытым
ключом D.
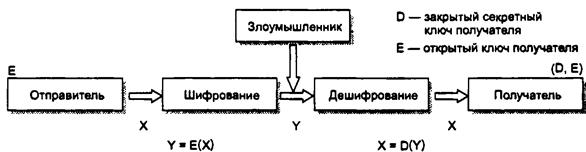
Рисунок 38. Модель криптосистемы с открытым ключом
Хотя информация об открытом ключе не является секретной, ее нужно защищать от подлогов, чтобы злоумышленник под именем легального пользователя не навязал свой открытый ключ, после чего с помощью своего закрытого ключа он может расшифровывать все сообщения, посылаемые легальному пользователю и отправлять свои сообщения от его имени. Проще всего было бы распространять списки, связывающие имена пользователей с их открытыми ключами широковещательно, путем публикаций в средствах массовой информации. Однако при таком подходе мы сталкиваемся с плохой масштабируемостью. Решением этой проблемы является технология цифровых сертификатов. Сертификат — это электронный документ, который связывает конкретного пользователя с конкретным ключом.
В настоящее время одним из
наиболее популярных криптоалгоритмов с открытым ключом является криптоалгоритм RSA.
В 1978 году трое ученых (Ривест, Шампр и Адлеман) разработали систему шифрования с открытыми ключами RSA (Rivest, Shamir, Adleman). Этот метод состоит в следующем:
1. Случайно выбираются два очень больших простых числа р и q.
2. Вычисляются два произведения n=p×q и m=(p-l)×(q-l).
3. Выбирается случайное целое число Е, не имеющее общих сомножителей с m.
4. Находится D, такое, что DE=1 по модулю m.
5. Исходный текст, X, разбивается на блоки таким образом, чтобы 0<Х<n.
6. Для шифрования сообщения необходимо вычислить С=ХE по модулю n.
7. Для дешифрирования вычисляется Х=СD по модулю n.
Программная реализация криптоалгоритмов типа RSA значительно сложнее и менее производительна, чем реализация классических криптоалгоритмов типа DES. Вследствие сложности реализации операций модульной арифметики криптоалгоритм RSA часто используют только для шифрования небольших объемов информации, например для рассылки классических секретных ключей или в алгоритмах цифровой подписи, а основную часть пересылаемой информации шифруют с помощью симметричных алгоритмов. в начало
74.
Односторонние
функции шифрования.
Односторонняя функция (one-way function) называется также хэш-функцией (hash function) или дайджест-функцией (digest function).
Эта функция, примененная к шифруемым данным, дает в результате значение (дайджест), состоящее из фиксированного небольшого числа байт. Дайджест передается вместе с исходным сообщением. Получатель сообщения, зная, какая односторонняя функция шифрования (ОФШ) была применена для получения дайджеста, заново вычисляет его, используя незашифрованную часть сообщения. Если значения полученного н вычисленного дайджестов совпадают, то значит, содержимое сообщения не было подвергнуто никаким изменениям. Знание дайджеста не дает возможности восстановить исходное сообщение, но зато позволяет проверить целостность данных.
Дайджест является своего рода контрольной суммой для исходного сообщения. Однако имеется н существенное отличие. В отличие от контрольной суммы при вычислении дайджеста требуются секретные ключи. В случае если для получения дайджеста использовалась односторонняя функция с параметром, который известен только отправителю и получателю, любая модификация исходного сообщения будет немедленно обнаружена.
Возможен другой вариант использования односторонней функции, когда она не имеет параметра-ключа, но зато применяется не просто к сообщению, а к сообщению, дополненному секретным ключом. Получатель, извлекая исходное сообщение, также дополняет его тем же известным ему секретным ключом, после чего применяет к полученным данным одностороннюю функцию. Результат вычислений сравнивается с полученным но сети дайджестом.
Помимо обеспечения целостности сообщений дайджест может быть использован в качестве электронной подписи для аутентификации передаваемого документа.
Построение односторонних функций является трудной задачей. Такого рода функции должны удовлетворять двум условиям:
1. по дайджесту, вычисленному с помощью данной функции, невозможно каким-либо образом вычислить исходное сообщение;
2. должна отсутствовать возможность вычисления двух разных сообщений, для которых с помощью данной функции могли быть вычислены одинаковые дайджесты.
Наиболее популярной в системах безопасности в настоящее время является серия хэш-функций MD2, MD4, MD5. Все они генерируют дайджесты фиксированной длины 16 байт. Адаптированным вариантом MD4 является американским стандарт SHA, длина дайджеста в котором составляет 20 байт. Компания IBM поддерживает односторонние функции MDC2 п MDC4, основанные на алгоритме шифрования DES. в начало
75.
Параметры,
свойства и показатели эффективности ОС.
К
операционным системам современных компьютеров предъявляется ряд требований. Главным
требованием является выполнение основных функций эффективного управления
ресурсами и обеспечения удобного интерфейса для пользователя и прикладных
программ. Современная ОС должна поддерживать мультипрограммную обработку,
виртуальную память, свопинг, развитый интерфейс, высокую степень защиты,
удобство работы, а также выполнять многие другие необходимые функции и услуги.
Кроме этих требований функциональной полноты, к ОС предъявляется ряд важных
эксплуатационных требований.
Под эффективностью вообще любой
технической (да и не только технической) системы понимается степень соответствия
системы своему назначению, которая оценивается некоторым множеством показателей
эффективности.
Поскольку ОС представляет собой
сложную программную систему, она использует для собственных нужд значительную
часть ресурсов компьютера. Часто эффективность ОС оценивают ее
производительностью (пропускной способностью) – количеством задач
пользователей, выполняемых за некоторый промежуток времени, временем реакции на
запрос пользователя и др.
На
все эти показатели эффективности ОС влияет много различных факторов, среди
которых основными являются
архитектура ОС, многообразие ее функций, качество программного кода, аппаратная
платформа (компьютер) и др. в начало
76.
Основные и
частные показатели эффективности ОС.
Основные показатели эффективности операционной системы:
·
Производительность - количество задач пользователей, выполняемых
за некоторый промежуток времени;
·
Относительная пропускная способность - вероятность
того, что заявка будет принята к обслуживанию;
·
Реактивность системы - время реакции на запрос пользователя;
·
Коэффициент задержки выполнения команд;
·
Коэффициент Полезного Действия.
Частные показатели эффективности операционной системы:
· Эффективность, характеризуемая ресурсоемкостью операционной системы;
· Надежность;
· Качество программного кода;
· Экономические показатели;
· Коэффициент использования центрального процессора;
· Коэффициент эффективности мультипроцессорной обработки. в начало
77.
Мониторинг
производительности ОС.
Наблюдение за производительностью системы является важной составной частью системы обслуживания и администрирования. Данные о производительности, полученные в ходе наблюдения, используются для выполнения следующих задач:
· определение рабочей нагрузки и ее влияние на ресурсы системы;
· обнаружение изменений и тенденций в рабочей нагрузке;
· диагностика работы конечных компонентов или процессов с целью их оптимизации, включая обнаружение и устранение неполадок;
Например, в состав стандартных инструментов Windows ХР Professional входят следующие средства наблюдения за использованием ресурсов компьютера:
· Диспетчер задач;
· компонент Системный монитор консоли Производительность;
· компонент Оповещения и журналы производительности консоли Производительность;
· некоторые утилиты командной строки.
Диспетчер задач представляет собой простое в использовании средство для получения основных данных о производительности локального компьютера.
В первую очередь это сведения о программах и процессах, выполняемых компьютером, а также информация об использовании процессора и памяти.
Компоненты консоли Производительность предоставляют подробные сведения о ресурсах, используемых конкретными объектами операционной системы. Пользователи могут получать эти данные в журналах в виде графиков, или же в специальной форме, предназначенной для дальнейшего анализа с помощью специализированных программ. в начало
78.
Настройка и
оптимизация ОС.
Большинство операционных систем непосредственно после установки имеют все настройки выставленные по-умолчанию – т.е. таким образом, чтобы операционная система могла выполнять любые функции на любом компьютере. Суть настройки операционной системы состоит в том, чтобы привести параметры системы под нужды конечного пользователя, а так же учесть специфику аппаратной части компьютера. в начало
79.
Прерывания
(понятие, классификация, обработка прерываний).
Прерывание (англ. interrupt) —
сигнал, сообщающий процессору о
наступлении какого-либо события. При этом выполнение текущей последовательности
команд приостанавливается, и управление передаётся обработчику прерывания, который реагирует на событие и обслуживает его, после чего
возвращает управление в прерванный код.
В зависимости от источника прерывания делятся на три больших класса:
· внешние;
· внутренние;
· программные.
Внешние прерывания могут возникать в результате действий пользователя или оператора за терминалом, или же в результате поступления сигналов от аппаратных устройств — сигналов завершения операций ввода-вывода, вырабатываемых контроллерами внешних устройств компьютера. Данный класс прерываний является асинхронным по отношению к потоку инструкций прерываемой программы. Аппаратура процессора работает так, что асинхронные прерывания возникают между выполнением двух соседних инструкций, при этом система после обработки прерывания продолжает выполнение процесса, уже начиная со следующей инструкции.
Внутренние прерывания, называемые также исключениями, происходят синхронно выполнению программы при появлении аварийной ситуации в ходе исполнения некоторой инструкции программы. Примерами исключений являются деление на нуль, ошибки защиты памяти, обращения по несуществующему адресу, попытка выполнить привилегированную инструкцию в пользовательском режиме и т. п.
Программные прерывания отличаются от предыдущих двух классов тем, что они по своей сути не являются «истинными» прерываниями. Программное прерывание возникает при выполнении особой команды процессора, выполнение которой имитирует прерывание, то есть переход на новую последовательность инструкций.
Прерывания обычно обрабатываются модулями операционной системы, так как действия, выполняемые по прерыванию, относятся к управлению разделяемыми ресурсами вычислительной системы — принтером, диском, таймером, процессором и т. п. Процедуры, вызываемые по прерываниям, обычно называют обработчиками прерываний, или процедурами обслуживания прерываний. Аппаратные прерывания обрабатываются драйверами соответствующих внешних устройств, исключения — специальными модулями ядра, а программные прерывания — процедурами ОС, обслуживающими системные вызовы. Кроме этих модулей в операционной системе может находиться так называемый диспетчер прерываний, который координирует работу отдельных обработчиков прерываний. в начало
80.
Средства вызова
процедур.
Операционная система, как однозадачная, так и многозадачная, должна предоставлять задачам средства вызова процедур операционной системы, библиотечных процедур. Она должна также иметь средства для запуска задач, а при многозадачной работе — средства быстрого переключения с задачи на задачу. Вызов процедуры отличается от запуска задачи тем, что в первом случае виртуальное адресное пространство задачи остается тем же, а при вызове задачи это адресное пространство полностью меняется.
Вызов процедуры без смены кодового сегмента в защищенном режиме процессора Pentium производится обычным образом с помощью команд JMP и CALL.
Для вызова процедуры, код которой находится в другом сегменте, процессор Pentium предоставляет несколько способов вызова, причем во всех используется защита, основанная на уровнях привилегий.
Прямой вызов процедуры из неподчинённого сегмента. Этот способ состоит в непосредственном указании в поле команды JMP или CALL селектора, который указывает на дескриптор нового кодового сегмента. Этот сегмент содержит код вызываемой процедуры. Базовый адрес сегмента, содержащийся в дескрипторе, и смещение, задаваемое в команде JMP или CALL, определяют начальный адрес вызываемой процедуры.
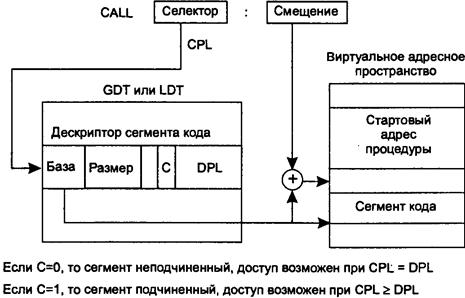
Рисунок 39. Прямой вызов процедуры
В первом случае запрет является естественным средством защиты ОС от вызова произвольных привилегированных процедур из пользовательских программ. Очевидно, что система защиты ОС не должна быть абсолютной, так как приложения должны иметь возможность обращаться к определенным процедурам ОС, реализующим системные вызовы. Так как с помощью неподчиненных кодовых сегментов этого сделать нельзя, то для решения этой проблемы существуют другие способы — подчиненные сегменты и шлюзы вызовов.
Во втором случае запрет звучит так: код не может вызвать другой код, если у последнего привилегии ниже. Это на первый взгляд кажется странным. Действительно, в соответствии с этим правилом операционная система не может вызывать код приложения из неподчиненного сегмента, хотя ее уровень привилегий выше, чем у кода приложения. Однако, по сути, этот запрет является проявлением общего иерархического принципа построения системы защиты процессоров Pentium — привилегированный код не может пользоваться ненадежными в общем случае процедурами с более низким уровнем привилегий, и этот принцип соблюдается для всех способов вызова процедур, а не только для данного.
Прямой вызов процедуры из подчиненного сегмента. Процессор должен поддерживать способ безопасного вызова модулей ОС, чтобы пользовательские программы могли получать доступ к службам ОС, например, выполнять ввод-вывод с помощью соответствующих системных вызовов. Для реализации этой возможности существует несколько способов, и одним из них является размещение процедур ОС в подчиненном сегменте (С=1). Подчиненный сегмент можно вызывать с помощью указания его селектора в командах CALL или JMP из кода программ с равным или более низким уровнем привилегий (CPL>DPL). Но нужно иметь в виду, что вызываемый код будет в этом случае выполняться с привилегиями вызывающей программы. Например, если код ОС, хранящийся в сегменте с уровнем привилегий 0, будет вызван из пользовательского приложения с уровнем привилегий 3, то процедура ОС будет наследовать привилегии пользовательской программы и возможности этой процедуры по доступу к системным данным будут весьма ограничены. Тем не менее выполнить действия над пользовательскими данными вызванная таким способом процедура ОС сможет.
Косвенный вызов процедуры через шлюз. Очевидно, что оба рассмотренных выше способа вызова процедур не подходят для реализации системных вызовов. Первый способ в принципе не позволяет вызвать из пользовательской программы с третьим уровнем привилегий процедуру операционной системы, находящуюся в неподчиненном сегменте и имеющую более высокий уровень привилегий. С помощью второго способа могут быть вызваны процедуры ОС, находящиеся в под-чиненном сегменте, однако они будут выполняться с пользовательским уровнем привилегий и не смогут обрабатывать системные данные, что нужно для большинства системных вызовов. Поэтому процессор Pentium предоставляет еще один способ вызова подпрограмм — через шлюз, позволяющий пользовательскому коду вызывать привилегированные процедуры, которые будут работать со своим высоким уровнем привилегий. Шлюзы вызова обладают еще одним преимуществом — появляется возможность контроля точек входа в вызываемые процедуры.
Схема вызова процедуры через шлюз приведена на рисунке. Селектор из поля команды CALL указывает на дескриптор шлюза в таблицах GDT или LDT. Для того чтобы получить доступ к процедуре через шлюз, описываемый данным дескриптором, вызывающий код должен иметь не меньший уровень прав, чем дескриптор шлюза (то есть CPL<DPL). При этом вызываемый код может иметь любой уровень привилегий (в том числе и более высокий, чем у шлюза), который сохраняется при его выполнении. Это позволяет из пользовательской программы вызывать процедуры ОС, работающие с высоким уровнем привилегий. При определении адреса входа в вызываемом сегменте смещение из поля команды CALL не используется, а используется смещение из дескриптора шлюза, что не дает возможности задаче самой определять точку входа в защищенный кодовый сегмент.
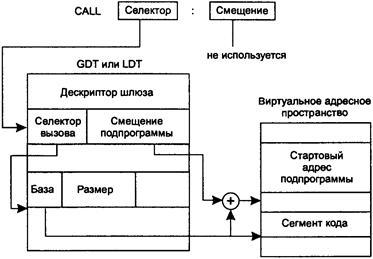
Рисунок 40. Вызов подпрограммы через шлюз вызова. в начало
81.
Механизм вызова
при переключении между задачами.
Механизм вызова при переключении между задачами отличается от механизма вызова процедур. В этом случае селектор команды CALL должен указывать на дескриптор системного сегмента TSS. Сегмент TSS хранит контекст задачи, то есть информацию, которая нужна для восстановления выполнения прерванной в произвольный момент времени задачи. Контекст задачи включает значения регистров процессора, указатели на открытые файлы и некоторые другие, зависящие от операционной системы, переменные. Скорость переключения контекста в значительной степени влияет на производительность многозадачной операционной системы.
Как и в случае вызова процедуры, имеются два способа вызова задачи — непосредственный вызов путем указания селектора дескриптора сегмента TSS нужной задачи в поле команды CALL и косвенный вызов через шлюз вызова задачи.
Однако условие, разрешающее непосредственный вызов задачи, отличается от условия непосредственного вызова процедуры: вызов возможен только в случае, если вызывающий код обладает уровнем привилегий, не меньшим, чем вызываемая задача (CPL<DPL). Здесь применяется то же правило, что и при доступе к данным. Действительно, операционная система, работающая с высоким уровнем привилегий, должна иметь возможность запускать на выполнение пользовательские задачи, работающие с низким уровнем привилегий. В этом случае ОС не поручает ненадежному низкоуровневому коду выполнять некоторые свои функции, как это происходило бы при вызове низкоуровневых процедур, а просто выполняет переключение между пользовательскими процессами.
При вызове через шлюз вызывающему коду достаточно иметь права доступа к шлюзу, а шлюз может указывать на дескриптор TSS в таблице GDT с равным или более высоким уровнем привилегий. Поэтому через шлюз вызова задачи можно выполнить переключение на более привилегированную задачу.
Непосредственный вызов задачи показан на рисунке. При переключении задач процессор выполняет следующие действия:
1. Выполняется команда CALL, селектор которой указывает на дескриптор сегмента типа TSS. Происходит проверка прав доступа, успешная при CPL<DPL;
2. В TSS текущей задачи сохраняются значения регистров процессора. На текущий сегмент TSS указывает регистр процессора TR, содержащий селектор сегмента;
3. В TR загружается селектор сегмента TSS задачи, на которую переключается процессор;
4. Из нового TSS в регистр LDTR переносится значение селектора таблицы LDT в таблице GDT задачи;
5. Восстанавливаются значения регистров процессора (из соответствующих полей нового сегмента TSS);
6. В поле селектора возврата нового сегмента TSS заносится селектор сегмента TSS снимаемой с выполнения задачи для организации возврата к ней в будущем.
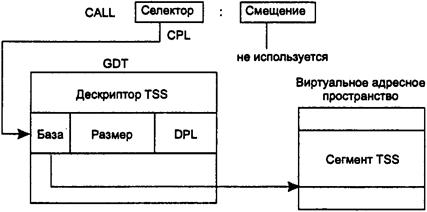
Рисунок 41. Непосредственный вызов задачи
Вызов задачи через шлюз происходит аналогично, добавляется только этап поиска дескриптора сегмента TSS по значению селектора дескриптора шлюза вызова. в начало
82.
Обработка аппаратных
прерываний.
Аппаратные прерывания бывают маскируемыми и немаскируемыми.
Маскируемые прерывания вызываются сигналом INTR на одном из входов микросхемы процессора. При его возникновении процессор завершает выполнение очередной инструкции, сохраняет в стеке значение регистра признаков программы EFLAGS и адреса возврата, а затем считывает с входов шины данных байт вектора прерываний и в соответствии с его значением передает управление одной из 256 процедур обработки прерываний.
Маскируемость прерываний управляется флагом разрешения прерываний IF (Interrupt Flag), находящимся в регистре EFLAGS процессора. При IF-1 маскируемые прерывания разрешены, а при IF-0 — запрещены. Для явного управления флагом IF в процессоре имеются чувствительные к уровню привилегий инструкции разрешения маскируемых прерываний STI (Set Interrupt flag) и запрета маскируемых прерываний CLI (CLear Interrupt flag). Эти инструкции разрешается выполнять при CPL≤IOPL. Кроме того, состояние флага изменяется неявным образом в некоторых ситуациях, например он сбрасывается процессором при распознавании сигнала INTR, чтобы процессор не входил во вложенные циклы процедуры обработки одного и того же прерывания. Процедура обработки прерывания завершается инструкцией IRET, по которой происходит извлечение из стека признаков EFLAGS, адреса возврата, установка флага разрешения прерываний IF и передача управления по адресу возврата. Для маскируемых прерываний в процессоре отведены процедуры обработки прерываний с номерами 32-255. Соответствие между сигналом запроса прерывания на шине ввода-вывода (например, сигналом IRQn на шине PCI) и значением вектора задается внешним по отношению к процессору блоком компьютера — контроллером прерываний.
Немаскируемое
прерывание происходит при появлении сигнала NMI (Non Maskable Interrupt) на входе процессора. Этот сигнал всегда
прерывает работу процессора, вне зависимости от значения флага IF. При обработке
немаскируемого прерывания вектор не считывается, а управление всегда передается
процедуре с номером 2, описываемой третьим элементом таблицы процедур обработки
прерываний. Немаскируемые прерывания предназначаются для реакции на
«сверхважные» для компьютерной системы события, например сбой по питанию. В
ходе процедуры обслуживания немаскируемого прерывания процессор не реагирует на
другие запросы немаскируемых и маскируемых прерываний до тех пор, пока не будет
выполнена команда IRET. Если при обработке немаскируемого прерывания возникает
новый сигнал NMI, то он фиксируется и обрабатывается после завершения обработки
текущего прерывания, то есть после выполнения команды IRET.
При одновременном возникновении
запросов прерываний различных типов процессор Pentium разрешает коллизию с
помощью приоритетов. Немаскируемые
прерывания имеют более высокий приоритет, чем маскируемые. Приоритетность
внутри маскируемых прерываний устанавливается не процессором, а контроллером
прерываний (процессор не может этого сделать, так как для него все маскируемые
запросы представлены одним сигналом INTR). Проверка некорректных ситуаций,
порождающих исключения, выполняется в процессоре в соответствии с определенной
последовательностью. в
начало
©Абашин А.Ю., Корогодова А.О., Олифер
В.Г., Олифер Н.А., Романович Н.К., Рудневский А.Ю., Хуторов В.С.